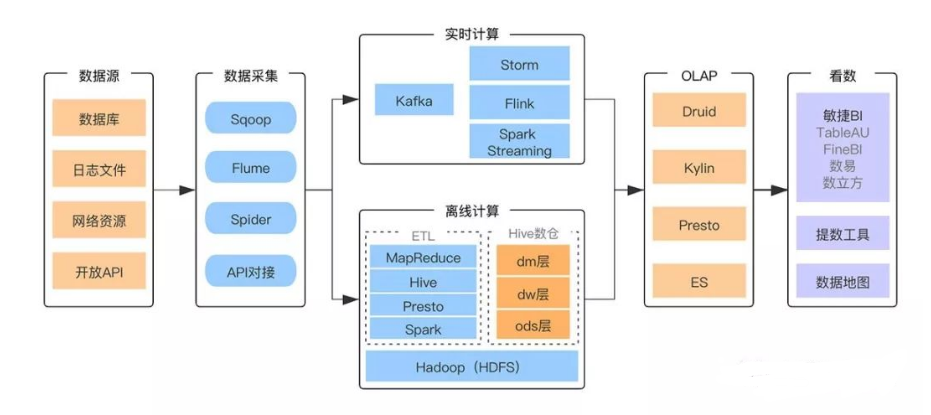
在数据量庞大的今天,互联网企业的数据处理过程犹如一场精心编排的演出,而各种技术选择就好比是手中的工具,各有其独特的优势。探究我国互联网企业广泛运用的大数据平台架构与技术选择,就如同拨开行业发展背后的重重迷雾。
采集数据来源
业务系统是数据采集的主要来源,也是大数据的起点。在这些系统中,结构化数据通常存储在关系型数据库中,井然有序,比如电商平台的商品信息。此外,还有半结构化数据,它们多记录在日志文件中,以网络服务的日志为例,其中蕴含着用户行为、操作记录等宝贵信息。这些信息种类繁多,为大数据处理提供了坚实的基础,对数据挖掘和用户行为分析都至关重要。数据采集是整个流程的基石,没有这一基础,后续的分析和处理便无从谈起。
实时计算数据通道
实时计算对时效性有着极高的要求,这和战场上对情报传输的及时性要求相似。通常,它通过Kafka与业务系统搭建实时数据通道来实现数据传输。Kafka就像一座桥梁,架起了两端数据流通的桥梁。在众多实时监控系统,比如监控网络流量的软件中,数据需要迅速传输以进行及时分析处理,这时Kafka的实时数据传输能力便能大显身手。这种高效的传输方式确保了数据能迅速获取并立即得到处理。
Sqoop数据转移
Sqoop功能十分独特,它充当着关系型数据库与其他系统间数据传输的关键角色。若需将MySQL数据库中的销售数据导入HDFS以进行后续的大数据处理,或者将HDFS中处理过的数据导回关系型数据库以支持业务拓展分析,Sqoop都能发挥其优势。在企业进行数据迁移项目,如从旧系统迁移数据至新的大数据平台时,Sqoop能保证数据的准确无误,大大减少了人力和时间成本。
Flume数据处理
Flume就像一个数据的小工厂。它具备对数据进行基础处理的能力,还能将数据传输到各式各样的定制化接收方。在处理大型网站日志数据时,Flume能先对混乱的日志数据进行初步整理,剔除无用信息,再将有价值的数据导入到指定的存储区域,为后续的深入分析打下基础。若没有Flume进行这一初步整理,后续处理的工作难度将大大提升。
Hive搭建数仓之选
Hive通过类似SQL的语法,大大简化了脚本编写的过程。在构建数据仓库时,它无疑是最理想的选择。数据仓库需要整合和分类大量数据资源。比如,金融企业在建立数据分析平台以进行风险分析时,Hive能轻松处理来自多个渠道的数据。它允许用户通过简单的SQL查询语句轻松获取所需数据,无需编写繁琐的脚本,从而显著提升了开发效率。
Spark内存计算优势
Spark的问世标志着大数据计算领域的一次重大突破。它将磁盘的多点I/O操作转变为内存中的多线程处理,使得数据处理过程中内存的使用率提高,从而减少了磁盘I/O操作的次数。这样的改进使得处理速度比传统方法快了十倍。在数据挖掘领域,比如从大量用户消费数据中分析消费习惯,Spark能够迅速完成数据处理,显著提升结果获取的速度。然而,内存容量的大小对Spark的性能有所限制,这一点在使用时需要特别注意。
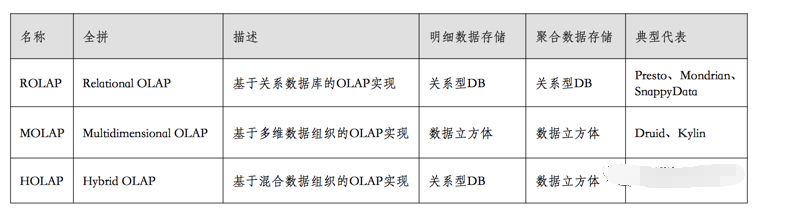
互联网公司在搭建大数据平台和选择技术时,必须全面考虑自身需求。那么,在你们公司处理大数据的过程中,最重视的技术特点是什么?期待各位读者朋友点赞、转发,并在评论区展开讨论。