

10月2日,成都的核酸检测系统出现了卡死和转圈圈的问题,导致操作人员不得不重新登录。这一现象引起了广泛关注,同时也给市民的正常核酸检测带来了困扰,确实让人感到烦恼。显然,这其中必定有着一定的原因值得我们去探究。

核酸系统的高要求情境

成都市民很少离开小区,导致检测点进入小区后的工作量急剧上升。这种业务量的突然激增,对核酸系统的要求非常高。以某个小区为例,原本每天的核酸检测人数仅有几百,现在却一下增加到几千。在这种状况下,系统的应对能力承受着巨大的考验。如果系统设计时未考虑到这种情况,很容易出现故障。平时检测点数量较少时,系统可能运行正常,但一旦面临更多的检测任务,就可能无法应对。这就像平时车辆稀少的道路,在节假日车流量激增时,很容易变得拥堵不堪。
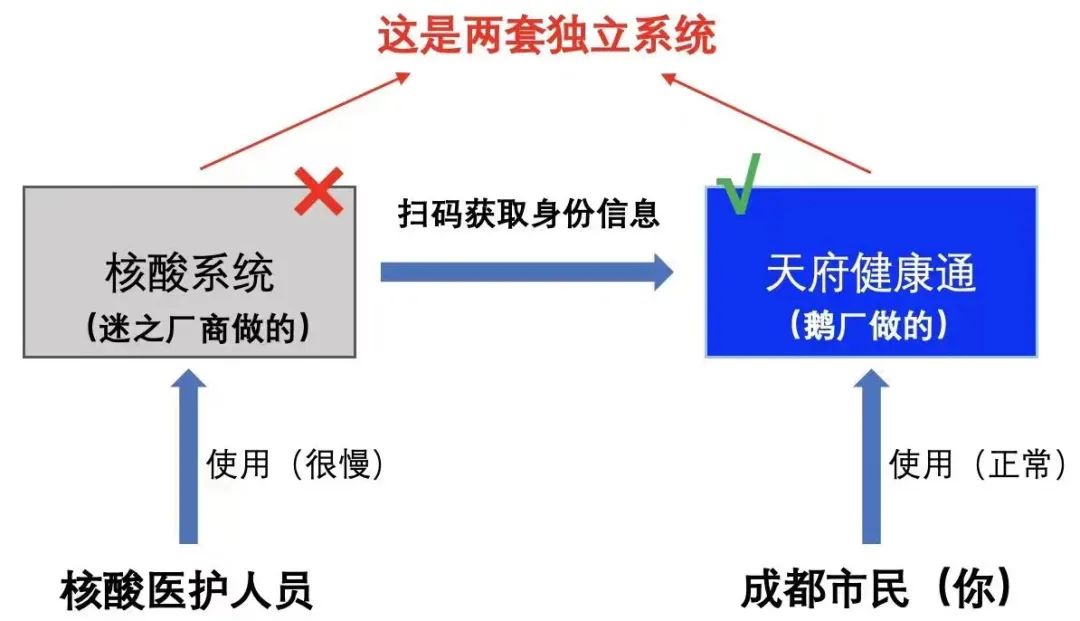
正常情况下区县检测系统运行无恙,但遇到大规模特殊检测,系统的不足便显现出来。2号大规模使用时出现的卡顿等问题,正是这一点的体现,显然是系统设计不够周全所致。
水平扩展与系统架构

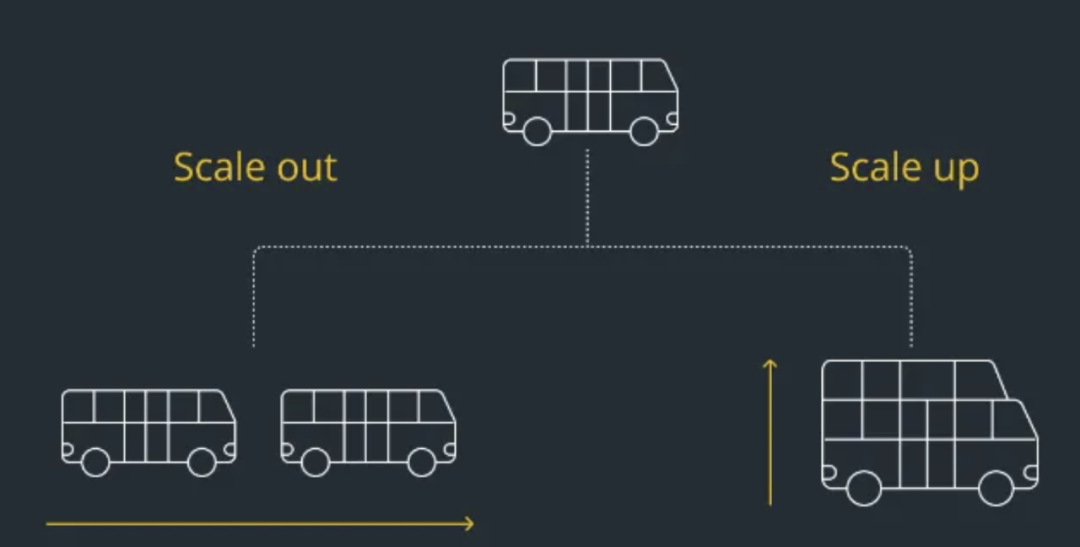
水平扩展对核酸系统至关重要。在有些情况下,单台服务器难以承受巨大的业务量,这时就需要增加服务器。观察成都核酸系统2号的运行情况,其架构设计似乎难以实现这一扩展。如果架构设置不合理,即使增加服务器数量,也可能无法解决问题。
系统在将待检测人员信息添加到检测人员列表时,反应迟缓且容易死机,这很可能是因为数据写入时出现了问题。这种情况很可能揭示了系统架构上的缺陷。如果架构设计得更为合理,那么这样的数据写入操作就不会如此困难,或许可以像高效的快递物流系统一样,实现信息的快速录入和流转。
数据处理策略之需
分库对于提高数据库性能至关重要。就好比不能把所有居民都挤在一个小区里一样,数据若分散存储于不同库中,就能有效避免拥堵。若成都的核酸系统实施了分库策略,那么2号系统出现的严重卡顿现象或许就能避免。
分表操作道理相通。依据日期或是区域来划分表格,能有效缩减单张表的数据量,进而缓解读写时的拥堵状况。比如,采用区域分表,每个区域的数据都独立存储在不同的表中,这样一来,在查询或写入时,冲突的可能性就会降低。然而,根据2号核酸检测的结果来看,成都的核酸系统似乎并未采取这种处理方式。
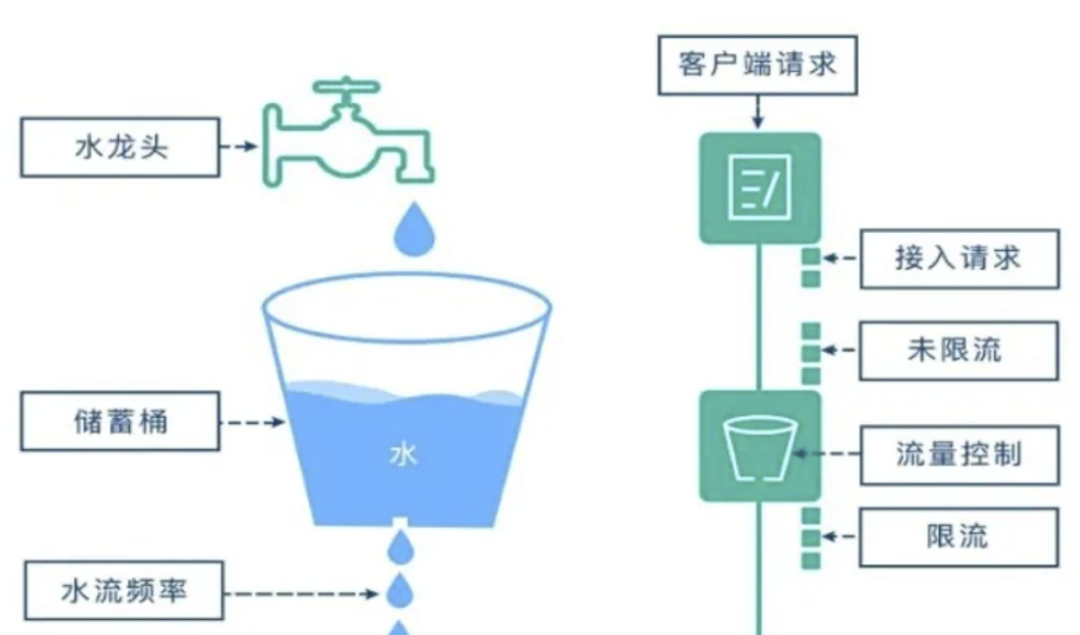
读写分离作用

读写分离技术有助于减轻数据库的压力。在主库负责写入数据,其他库负责查询的这种模式下,系统性能可以得到显著提升。成都的核酸系统可能正是因为缺少这种操作,在大量数据并发写入时直接陷入瘫痪。若实施读写分离,就如同分工明确的团队,各司其职,整体效率却能大幅提高。若不采取这一措施,数据容易积压拥堵,最终可能导致系统崩溃。
业务逻辑与表现反差
业务逻辑虽不复杂,但成都2号核酸系统却遭遇了卡顿和瘫痪。这种情况主要暴露出架构设计上的缺陷。系统无法处理原本应顺畅完成的任务,这表明在设计中未能充分预见高并发情况可能带来的后果。
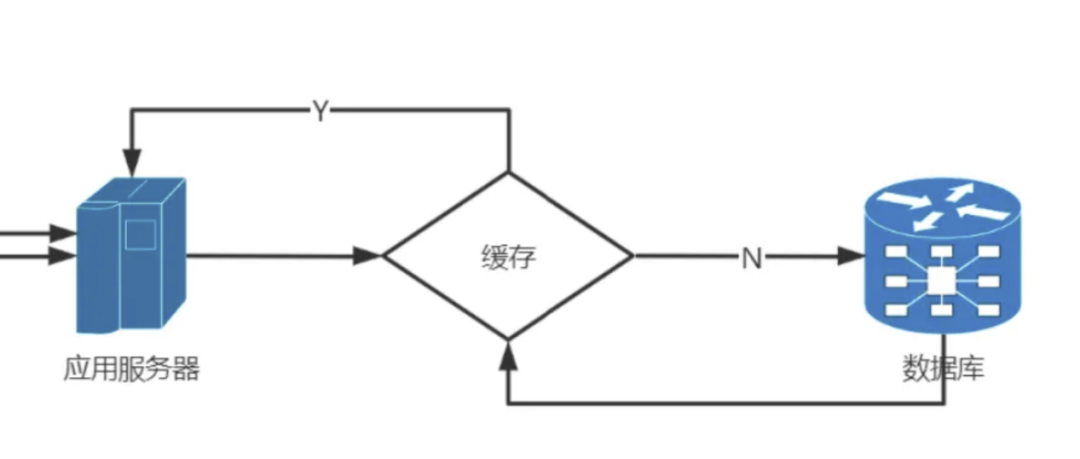
它可能没有配置缓存系统,因此所有数据都直接写入或读取数据库。这情形就好比一条河流失去了堤坝的约束,洪水便会肆无忌惮地冲击。在大量数据的冲击下,数据库显然难以承受。
问题根源探寻与优化建议
这个问题与网络、天府健康通、政务云资源均无关联。政务云资源具有按需动态分配的特性,满足业务需求并不特别困难。因此,我们确实需要从成都核酸系统本身寻找问题的根源。
衷心期盼那家开发核酸系统的公司能迅速查明问题所在并进行改进。若下次情况依旧,成都市民进行核酸检测恐怕又要面临混乱。大家不妨想想,若全员核酸检测再次因系统故障而停滞,耽误检测进度,岂不让人十分恼火?希望各位能共同讨论这个问题,并希望大家能点赞并转发这篇文章。











