
在当前的计算界,CUDA编程正慢慢崭露头角。特别地,核函数调用这一并行计算的核心概念,既凸显了其优势,也成为了难点,这一点非常值得深入研究。

CUDA核函数的重要性

CUDA的核心函数是并行计算的核心所在。它在多个线程中同时运行,通过特定的符号进行声明。在调用时,需要指定线程的数量,每个线程都必须执行任务,并且每个线程都有一个唯一的标识,可以通过内置变量获取。比如,在众多复杂的计算任务中,核函数就如同一位指挥官,调度着众多线程协同工作。在数据挖掘或图像处理等实际应用中,核函数能显著提升计算效率,其在并行计算领域的作用至关重要。此外,这一概念与传统编程中的函数有着本质的不同,是学习CUDA编程的基础和关键。
此外,熟悉核函数的调用规范等,同样是运用CUDA编程不可或缺的基石。举例来说,若要确保线程数量适宜,否则便可能无法实现计算效果的最优化。
dim3 grid(3, 2);
dim3 block(5, 3);
kernel_fun<<>>(prams...);
区分host和相关代码

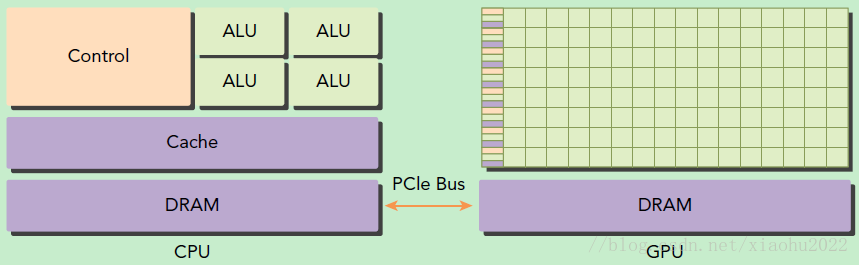
GPU作为异构模型,明确host与代码间的界限至关重要。在CUDA编程中,我们通过函数类型限定词来区分二者。这一设定是基础性的。若缺乏这种区分,编程时很容易混淆代码的执行环境。在实际开发中,开发者通常需要在host编写初始化代码、设置参数等,再将相应的代码任务分配到上执行。若区分不明确,程序逻辑可能会混乱,效率也可能低下。
threadIdx.x = 1
threadIdx.y = 1
blockIdx.x = 1
blockIdx.y = 1
这种区分仿佛两条并行轨道上的列车,各自独立行驶,互不干扰,却共同构成了一个完整项目的关键环节。它不仅能够显著提升代码的易读性,还能增强其可维护性。
线程结构剖析
启动后的所有线程构成了一个网格,这个网格中的线程共同使用一个全局的内存空间,这构成了线程结构的最初层级。而网格又可以细分为众多线程块,每个线程块中聚集了多个线程,这样就形成了第二层结构。比如在执行矩阵运算时,这种结构显得尤为适用。
// Kernel定义
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel 线程配置
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
// kernel调用
MatAdd<<>>(A, B, C);
...
}
要知晓线程在block中的唯一标识,必须掌握block的内部构造。这种结构有其独特之处,能够根据不同的计算需求灵活调整线程的布局。在那些需要细致分割任务的项目里,精确掌握线程的具体位置信息显得尤为重要。在这种情形下,这种线程的组织方式能够展现出其出色的功能。

SM的核心组件与架构特点
SM拥有CUDA核心、共享内存以及寄存器等关键组成部分。该架构具备并行处理数百线程的能力,其并发性能与所拥有的资源数量紧密相关。在具体项目实施中,硬件资源的数量直接影响到SM的并发处理能力。
SM系统采用了一种特定的架构,其基本执行单元为线程束,每个线程束由32个线程组成。这些线程会同时执行相同的指令,同时它们各自拥有指令地址计数器和寄存器状态。这可以比作一群士兵,他们听到同一指令后同时出发,但每位士兵都有自己的状态和行进路线。
GPU硬件配置检查的必要性

在开始CUDA编程之前,检查GPU的硬件配置至关重要。因为不同的硬件配置对CUDA编程有着显著的影响。若对硬件配置一无所知,所编写的程序可能无法充分利用硬件的优势。比如,若不清楚GPU的CUDA核心数量,编写核函数时调用过多线程可能会导致资源过度占用或浪费。
通过特定程序,我们可以获取GPU的配置属性。这就像在战斗前了解自己的武器装备。如此一来,我们能够有的放矢,编写出更加优化的CUDA程序。
CUDA编程实战之向量加法
int dev = 0;
cudaDeviceProp devProp;
CHECK(cudaGetDeviceProperties(&devProp, dev));
std::cout << "使用GPU device " << dev << ": " << devProp.name << std::endl;
std::cout << "SM的数量:" << devProp.multiProcessorCount << std::endl;
std::cout << "每个线程块的共享内存大小:" << devProp.sharedMemPerBlock / 1024.0 << " KB" << std::endl;
std::cout << "每个线程块的最大线程数:" << devProp.maxThreadsPerBlock << std::endl;
std::cout << "每个EM的最大线程数:" << devProp.maxThreadsPerMultiProcessor << std::endl;
std::cout << "每个EM的最大线程束数:" << devProp.maxThreadsPerMultiProcessor / 32 << std::endl;
// 输出如下
使用GPU device 0: GeForce GT 730
SM的数量:2
每个线程块的共享内存大小:48 KB
每个线程块的最大线程数:1024
每个EM的最大线程数:2048
每个EM的最大线程束数:64
在掌握了CUDA编程的基础之后,我们可以通过实际操作两个向量的加法来加深理解。在这个过程中,内存管理API扮演了至关重要的角色。它和C语言中的函数相似,申请显存时必须遵循一定的规范。同时,我们还需要释放内存,这与C语言的free函数相对应。此外,正确实现核函数、合理定义辅助函数以获取和赋值矩阵元素等,都是确保向量加法成功实施的关键环节。尤其是在进行大规模向量运算时,这些操作的精确度将直接影响到最终计算结果的准确性。
那么,你在CUDA编程过程中面临的最大难题是何?期待你能点赞、转发,并在评论区留下你的见解,让我们一起探讨。
cudaError_t cudaMalloc(void** devPtr, size_t size);







