

如今,软件开发界中,基于软件工程数据的模型训练效果显著,这一点尤为引人注目。这些模型在自动处理实际问题方面,已接近闭源模型,这一成就无疑在业界引起了广泛关注。
背景与挑战
近年来,软件开发领域遇到了不少难题。项目变得越来越复杂,对能够自动解决问题的智能体提出了更高的要求。这要求智能体拥有多种能力,比如在项目实际操作中,代码可能分布在不同的模块,需要准确理解代码库、找出问题所在、生成有效的代码并进行程序修复,才能全面解决实际问题。以某个大型项目为例,代码行数超过百万,开发团队在查找问题时常常需要花费大量时间。如果能有一个智能模型能够解决这些问题,无疑会极大地提高工作效率。在不同的开发环境中,资源条件也各不相同。对于一些资源有限的小型开发团队来说,他们对于在资源受限条件下仍能表现出色的模型有着强烈的需求。
这显示了当前行业存在的矛盾现象。一方面,人们迫切需要高效的问题解决模型;另一方面,又遭遇了多方面功能融合的难题。在此过程中,需突破众多技术难关,例如如何应对不同编程语言结构的区别等。
基于Qwen2.5的SWE-GPT
SWE-GPT基于Qwen2.5系列模型,拥有独特的工作方式。它从问题描述和代码库入手。将它们作为输入,相当于为模型设定了起点。比如在修复某金融软件漏洞时,开发者输入错误描述和软件代码库,SWE-GPT便如同资深程序员,开始模拟认知过程。
它的多阶段工作流程并非简单的线性序列,而是内含着错综复杂的内在逻辑。实际上,这一流程是对专家解决问题的关键思维过程的模拟。在现实开发环境中,专家往往需从多个角度审视问题,并可能频繁变换思考角度。SWE-GPT也在努力实现这种思维模式的模仿。
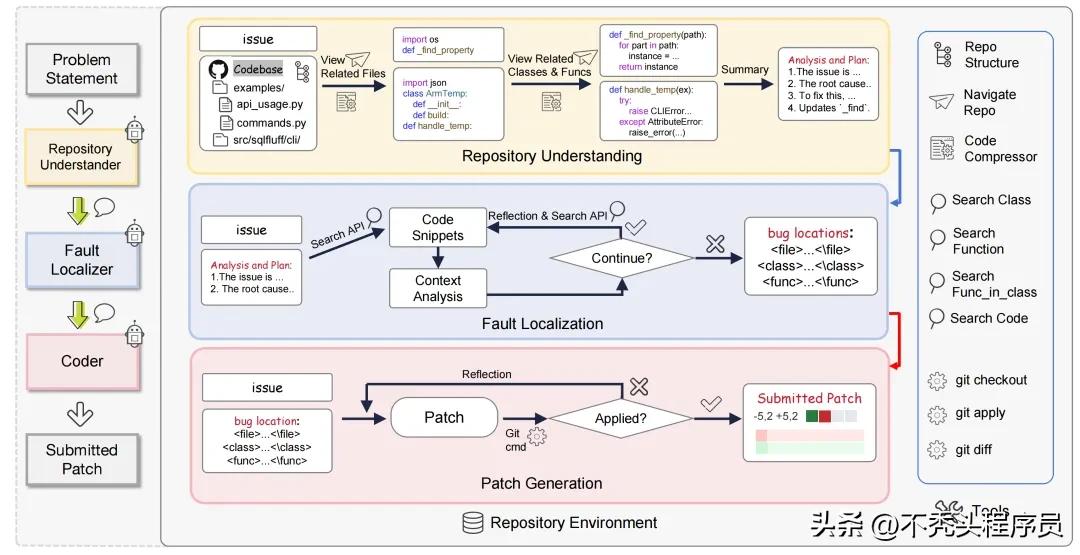
数据合成方法
该模型的数据构建过程分为三个关键步骤。首先,是基础性的仓库解析阶段。在开发人员浏览代码库时,他们需了解库的结构和模块划分。模型同理,需深入理解仓库内容。例如,在某个网络通讯软件的修复项目中,若模型无法正确把握仓库中关于网络通讯协议的代码架构,那么后续的工作将会面临很大挑战。
故障定位器在故障定位环节是必不可少的,它就像医生的诊断工具一样。软件一旦出现问题,准确找出故障点至关重要。比如,某图像编辑软件曾出现色彩显示异常,开发人员经过长时间搜索,最终发现是色彩转换算法代码出了问题。我们的模型在故障定位环节也要模拟开发者的复杂诊断过程,这涉及到使用工具和不断尝试解决方法。而补丁生成阶段,则是在此基础上进行最后的修复工作。
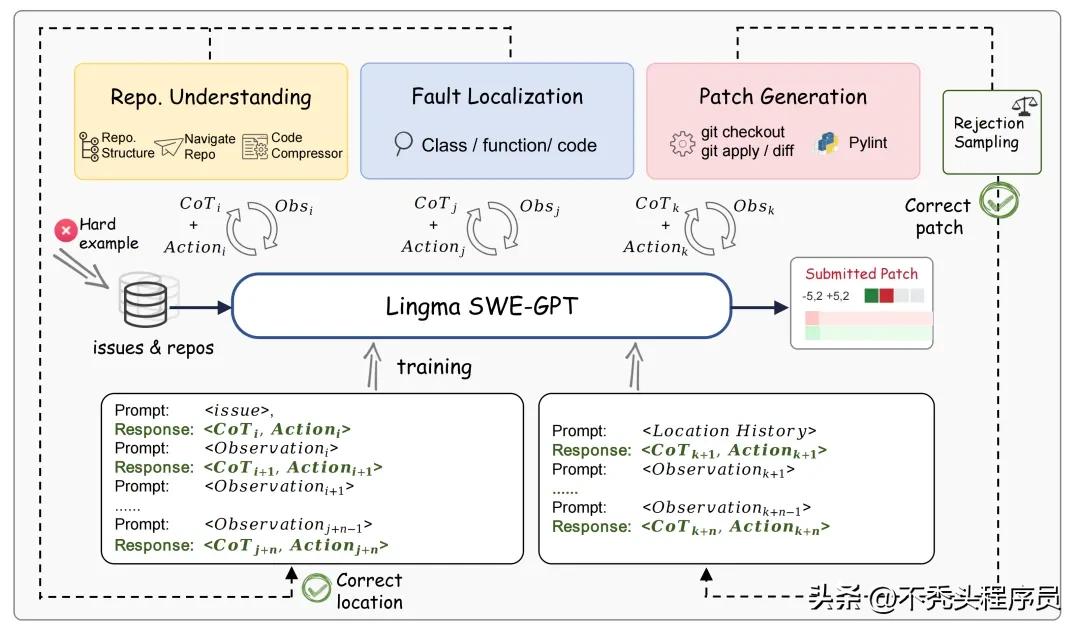
训练过程优化
为了增强模型训练的稳定性,我们将采用课程学习策略。以学生掌握新知识为例,他们通常是从基础内容开始,逐步深入到更复杂的内容。在模型训练过程中,我们会在迭代中引入越来越复杂且难以解决的问题样本。而在一些早期的模型训练中,常常对所有样本一视同仁,这导致模型在面对复杂样本时表现不佳。
为确保训练数据的高品质,拒绝采样也是一种关键手段。我们通过故障定位的精确度和补丁的相似度这两个标准来挑选案例。在具体的项目实践中,有些案例虽然故障定位准确,但生成的补丁却不相似,这时我们保留故障定位的步骤,而舍弃与补丁相关的操作。例如,在修复一款文档编辑软件的错误时,这种方法能有效筛选出众多有价值的中间推理案例。
性能评估方面
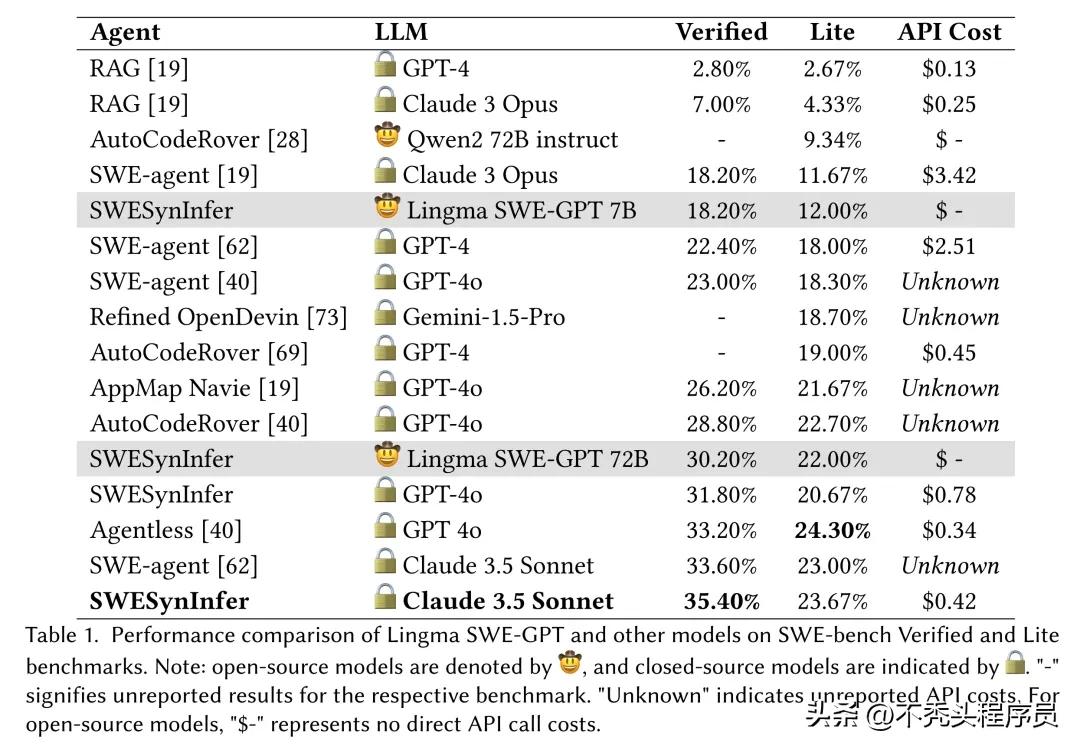
评估SWE-GPT性能时,我们使用了多种方法。在与其他开源模型进行比较时,我们使用了相同的推理流程。这相当于站在同一起跑线上进行比赛。在操作系统代码修复的测试中,不同模型在相同的推理测试中各有表现,有的好有的差。此外,为了专门检验这些模型在软件工程任务上的有效性,而非仅仅是指令跟随能力,我们还为部分开源模型量身定制了提示工程和工具。这就像为不同的运动员制定了个性化的比赛规则,非常细致。
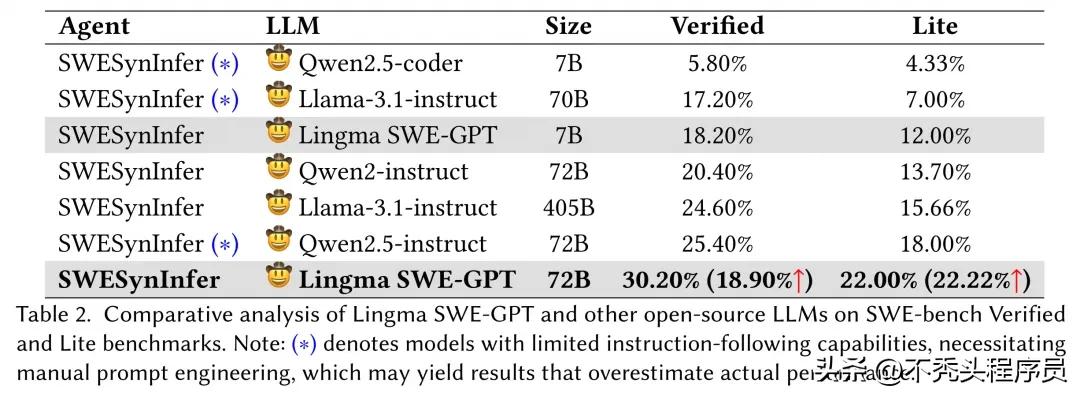
评估模型故障定位能力是判断其优劣的关键标准。SWE-GPT在生成补丁位置方面与实际位置的一致性上表现出色。尤其在游戏开发这类代码结构繁复的项目中,SWE-GPT在各个粒度级别上的故障定位能力都明显胜过其他开源模型,其表现甚至可与闭源模型GPT-4o相媲美。
未来发展展望
SWE-GPT已有成果,但发展潜力巨大。故障定位技术需加强。比如,加强代码理解能力,模型能更透彻理解代码逻辑。大型游戏公司代码逻辑复杂,若提升理解能力,故障定位能力或显著增强。运用更复杂的静态和动态分析同样可行。对于航空航天等安全性要求高的软件,此法能提升模型在开发中的表现。
7B版本成功解决了18.20%的问题,这表明即便在资源有限的情况下,小型模型仍有很大的发展空间。这一成果对众多资源有限的小型开发团队和项目来说,无疑是一个鼓舞人心的消息。
在此提出个问题,各位觉得SWE-GPT将来能在哪些新的软件开发领域中引发更深层次的变革?期待大家的讨论与交流,同时也希望大家能点赞并转发这篇文章。









