在当前大数据时代,市面上有许多用于处理和保存大量数据的软件架构。在这些架构中,有一款搭配工具引起了广泛关注。这款工具就是Hive。大家普遍知道它能够提升工作效率,但具体它是怎样的一个存在?这正是我们今天需要深入研究的课题。

一Hive的基础构成
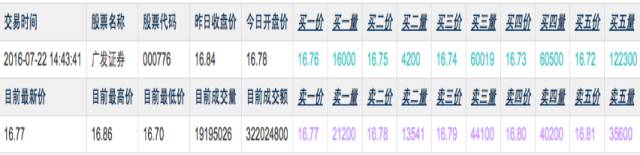
Hive系统由三个主要部分构成。首先是客户端,Hive支持多种驱动程序,以便与不同应用协同工作,比如与Java应用配合时,会使用Java客户端。接着是服务部分,这部分需要与执行客户端进行交互,例如,客户端执行查询时,必须与Hive服务进行沟通。最后是存储与计算部分,数据存储依赖于HDFS,而数据计算则依赖于其他相关组件。

Hive的结构设计有其合理性。它由多个部分组成,这些部分相互协作。客户端负责与各种应用进行连接,而服务则扮演着连接的桥梁角色。至于存储和计算部分,它们负责对数据进行管理。这些功能共同为数据处理的全过程搭建了一个稳固的框架基础。
功能特性分析
Hive功能丰富。它能建立索引,有助于提升数据检索效率。它支持多种存储格式,包括纯文本和HBase文件。此外,它将元数据存放在关系数据库里,显著缩短了查询语义验证所需的时间。Hive可以直接访问文件系统中的数据,并且内置了许多实用函数。比如,它有内置的UDF来处理不同类型的数据,还允许用户自定义功能。
这些功能特性并非完美,存在一些不足。以Hive的HQL为例,其表达能力受限,无法支持迭代式算法。此外,它的运行效率不高,自动生成的作业不够智能,且优化过程复杂,调整粒度较大。
查询功能剖析
Hive的查询功能独具特色。它运用类似SQL的语法进行操作,这样的设计使得开发变得迅速,用户可以轻松掌握。这样一来,用户无需编写繁琐的程序代码。而且,Hive SQL可以将SQL语句转化为可执行的任务,即便对底层不熟悉的用户也能轻松地进行数据查询、汇总和分析。
这种查询方式存在不足。因为Hive需将SQL查询转化为MapReduce任务在集群中运行,这造成了较高的执行延迟。因此,它多用于对实时性要求不高的数据分析,对于小数据量的处理也不具备明显优势。

操作模式分类
Hive能够根据数据节点的大小来调整运行模式。在本地模式中,它通常以伪模式安装,并且仅有一个数据节点。这种模式下,数据量较小,仅限于一台本地机器。尽管如此,由于数据集规模小,数据处理速度更快。
在MapReduce这种模式下,情况会有所不同。一旦存在多个数据节点,数据便会分散存储在这些节点上。这两种处理方式适用于不同的应用场景,用户需根据自身数据的具体特性来做出选择。
对不同数据量的适应性
在大数据处理领域,Hive展现出显著优势。它能够应对大量数据的处理需求。数据量增加时,Hive的架构表现良好,能有效应对。比如,它能充分利用分布式计算的优势。
处理少量数据时,它显得不够出色。硬件资源的调用、流程的复杂性等,都成了负担,导致执行速度慢,而且浪费了不必要的资源。
自定义函数的应用
Hive允许用户自己编写函数,这个功能非常方便。用户能按需创建函数。若现成的函数不能解决特定问题,这项功能就显得尤为重要。比如,某公司有独特的数据处理流程,其内部技术人员就能利用这个功能来编写专属函数。
用户自编的函数有特定条件,操作者需具备相应技能。若操作失当,可能导致系统出现故障等问题。
在处理大数据时,你更倾向于使用Hive吗?期待大家的点赞、转发,也欢迎在评论区交流看法。