
在电影产业快速发展的当下,对电影资料的细致分析和图形展示变得尤为关键。目前的研究多少有些不足,特别是针对豆瓣电影资料,运用Spark技术进行研究和展示的案例并不多见。本文正是填补这一空白的所在。
豆瓣电影数据的独特性
豆瓣电影的数据内容丰富多样。它不仅包括观众的评分,还有影评的具体内容,以及电影的众多标签。这些信息展现了从普通观众的观影偏好到电影文化的深层内涵等多个层面的情况。比如,通过分析不同时期热门电影的评分和影评,我们能看出观众喜好的转变。此外,这些数据数量庞大且结构复杂,对其进行处理分析具有一定的难度。运用Spark框架进行数据挖掘,可以高效地应对这些大规模的数据挑战。
豆瓣电影的数据汇集了多种信息渠道。其中包括观众自主给出的评分和评论,以及电影发行方提供的基础资料。因此,在数据整合和分析过程中,必须进行精心操作,以保证信息的精确无误。运用Spark框架来处理这些数据,可以更有效地提取出更有价值的内容。
Spark框架的优势
Spark在数据处理上非常迅速。与旧方法相比,它能够迅速地读取并处理豆瓣电影的大规模数据,有效提升了分析的速度。以豆瓣累积多年的电影评分数据为例,用传统方法可能需要数小时甚至数天,而Spark框架则能在较短的时间内完成这项任务。
Spark在处理复杂数据类型上表现得非常出色。豆瓣电影的数据中既有数值型的评分,还有文本型的影评等。Spark能够对这些不同类型的数据进行灵活的分析和处理。它简化了数据挖掘和分析的操作步骤,使得数据可视化变得更加高效。
系统功能模块构建
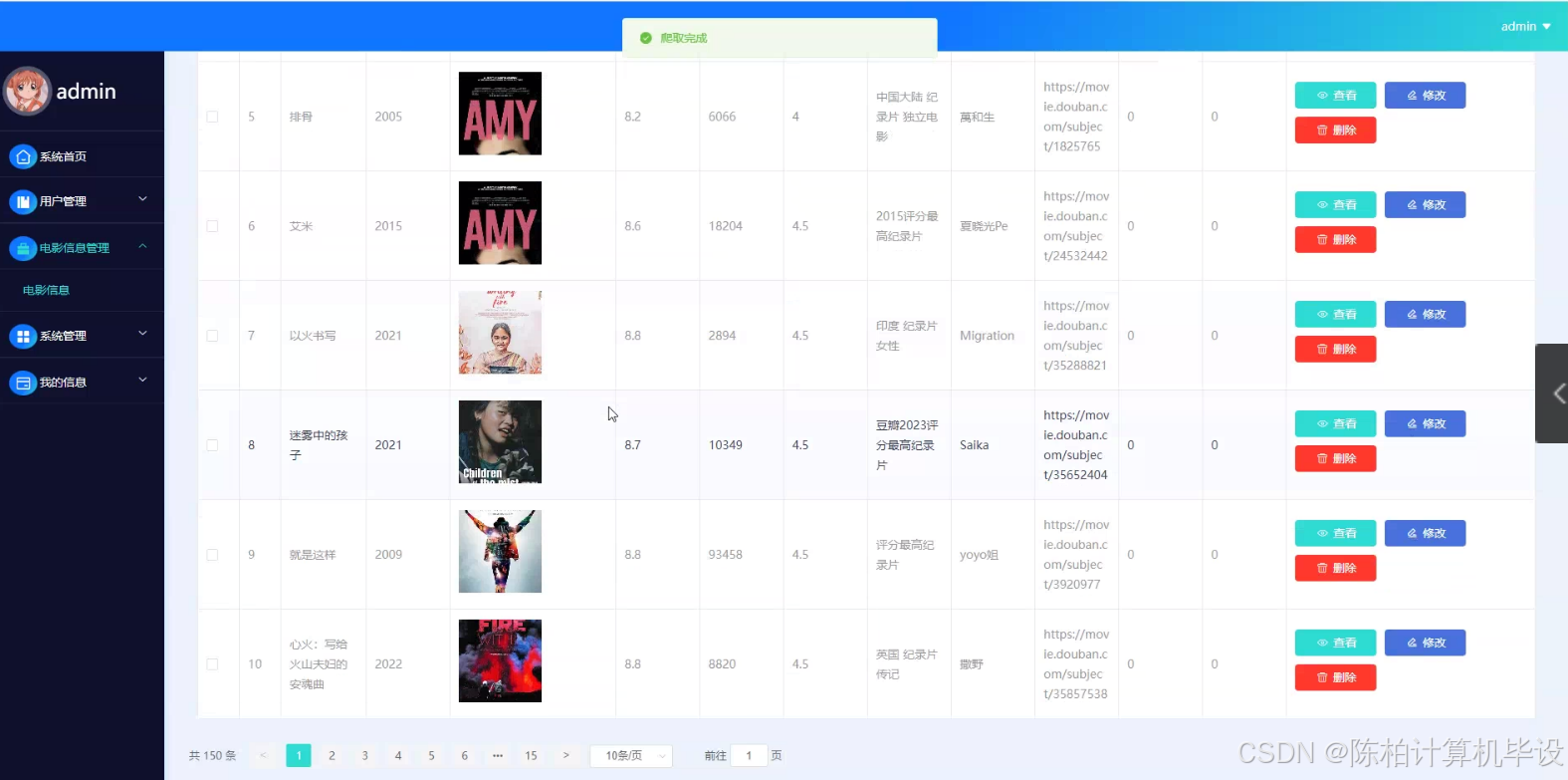
数据采集模块承担着搜集豆瓣电影相关信息的重任。它涉及电影的基础信息,如导演、演员以及上映日期等。在2024年3月到4月搭建工程环境期间,该模块便着手进行规划,旨在确保能够精确获取最新且详尽的数据。
该模块负责数据分析和可视化。它能对收集到的数据进行多角度分析,比如分析不同类型电影的评分变化趋势,并通过图表进行直观展示。在4月至5月的多平台联合测试阶段,我们特别对这一模块进行了细致的优化,目的是确保分析结果的准确无误呈现。
开发环境搭建
搭建后端环境。我们采用Node.js构建系统后端,成功创建项目并安装了必要的npm软件包。开发小组在既定的时间节点内推进搭建任务,比如在2024年3月至4月期间,他们逐步优化了后端环境,并设置了与本地MySQL数据库的连接,为数据的存储与调用打下了坚实的基础。
搭建前端开发环境。采用Vue.js等技术构建界面,结合界面设计及用户交互流程。开发全程,前端开发持续跟进,保证多平台测试后,页面稳定运行,为用户打造优质交互体验。
项目开发进程管理
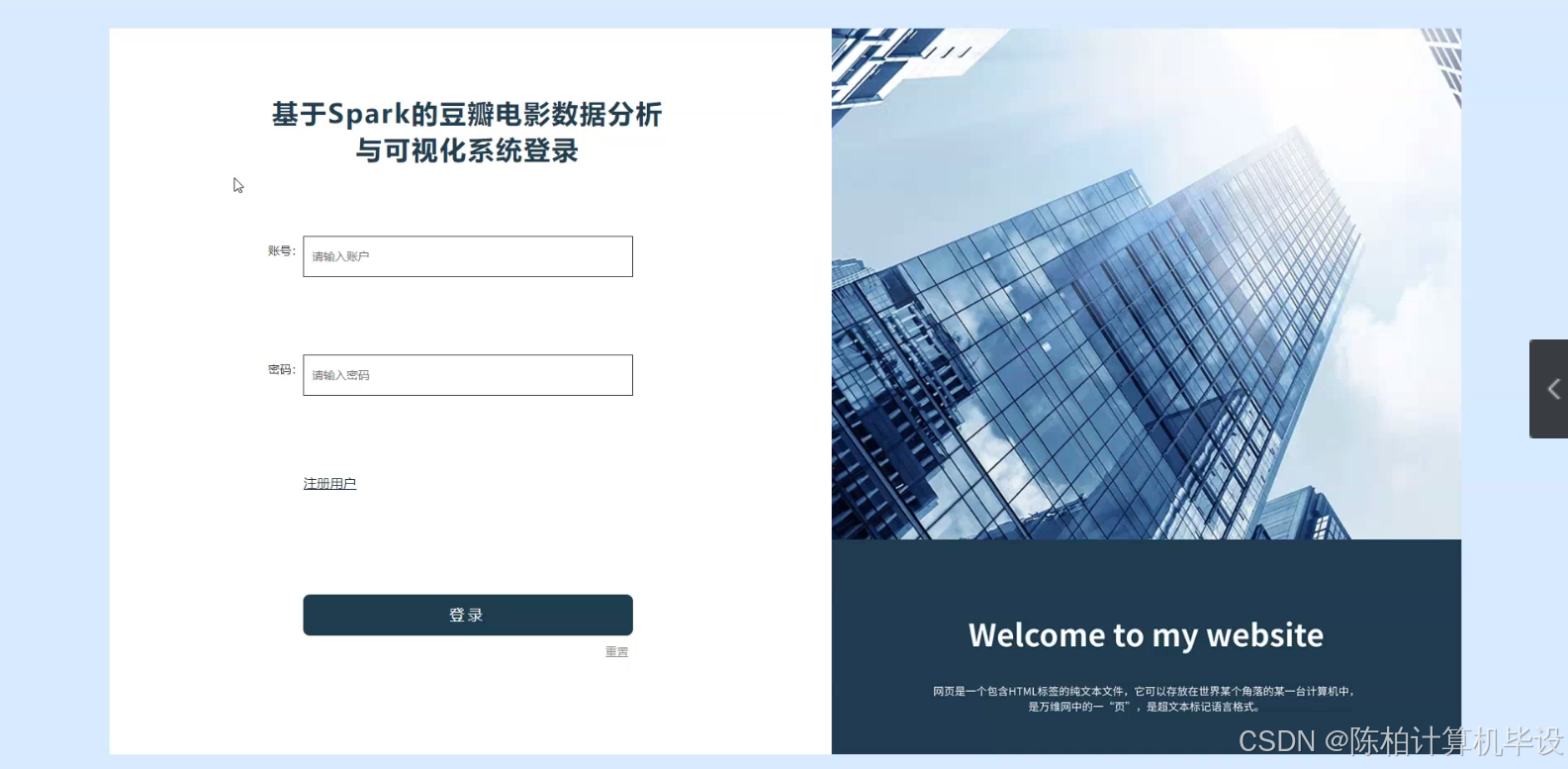
时间安排清晰。2024年3月6日至4月4日,将完成后端数据接口和前端管理页面的编写任务;接着,从4月4日至5月9日,将着手前端页面代码的编写、多平台联合测试以及修复bug等工作。这样的时间安排确保了项目的稳步推进。
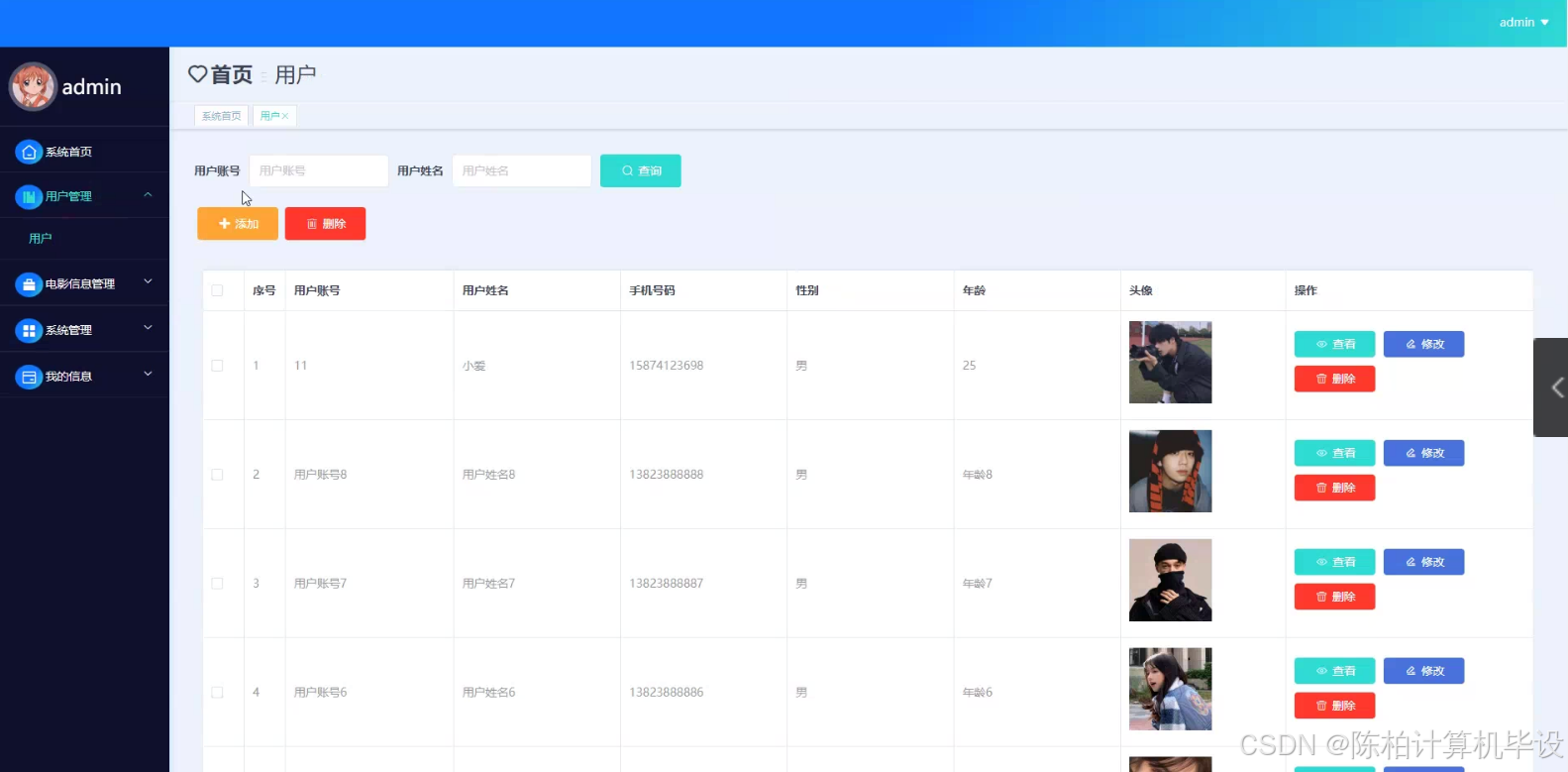
开发团队分工清晰。各类技术人员各尽其责,针对涉及的研究领域中的不同技术,比如Node.js、Vue.js、Spark框架等,都有专人负责相应的开发部分,确保不会因职责不清而耽误项目进度。
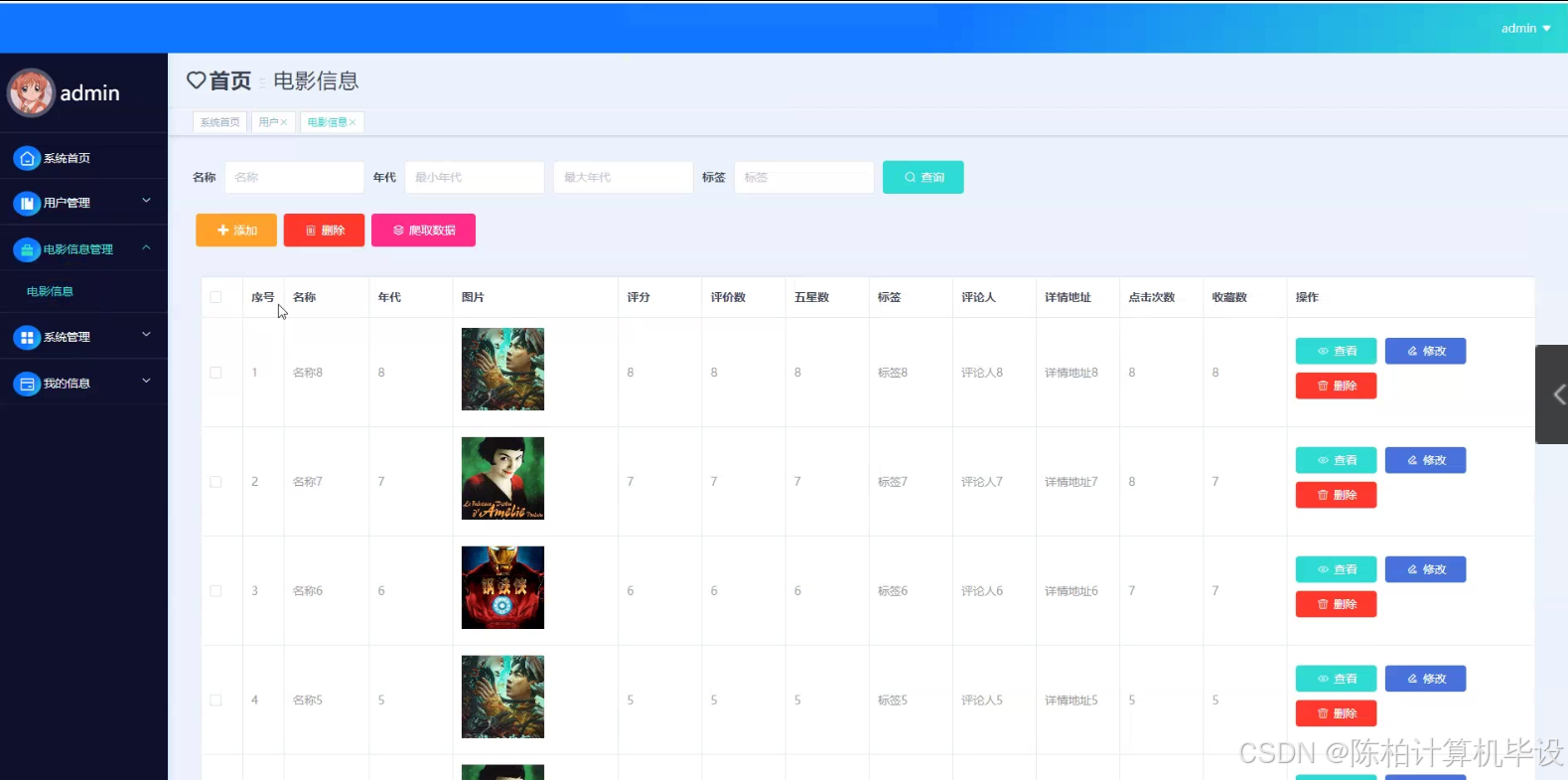
项目的意义和展望
该项目的理论价值在于,它丰富了大数据分析在特定领域(如豆瓣电影数据挖掘与分析)的理论框架,为该领域的数据分析研究提供了理论依据。比如,后续的研究可以参考本系统的分析方法。
实践价值显著。它为电影工作者带来了深入的数据见解。比如,电影制作者能依据大众的喜好倾向来调整他们的创作路线。当你浏览电影资讯时,是否意识到这样一个数据展示系统能带来如此多的益处?欢迎留言、点赞和转发。







