
在人工智能助力工作的当下时代,我们不禁要问:它是否真的能够胜任那些“具有实际经济价值”的繁复任务?我们又该如何评估其在这一领域的实际能力?这些问题已经成为众人关注的焦点。
传统评估方法的局限

目前对大型语言模型的评估,多使用GLUE、MMLU等标准测试。这些测试主要检查AI答题的能力,却不能体现其在实际应用中的表现。就像学生考试能答对题,并不意味着他们能胜任工作。这表明,传统的评估方式在评估AI工作能力上存在较大不足。
全新评估指标的提出
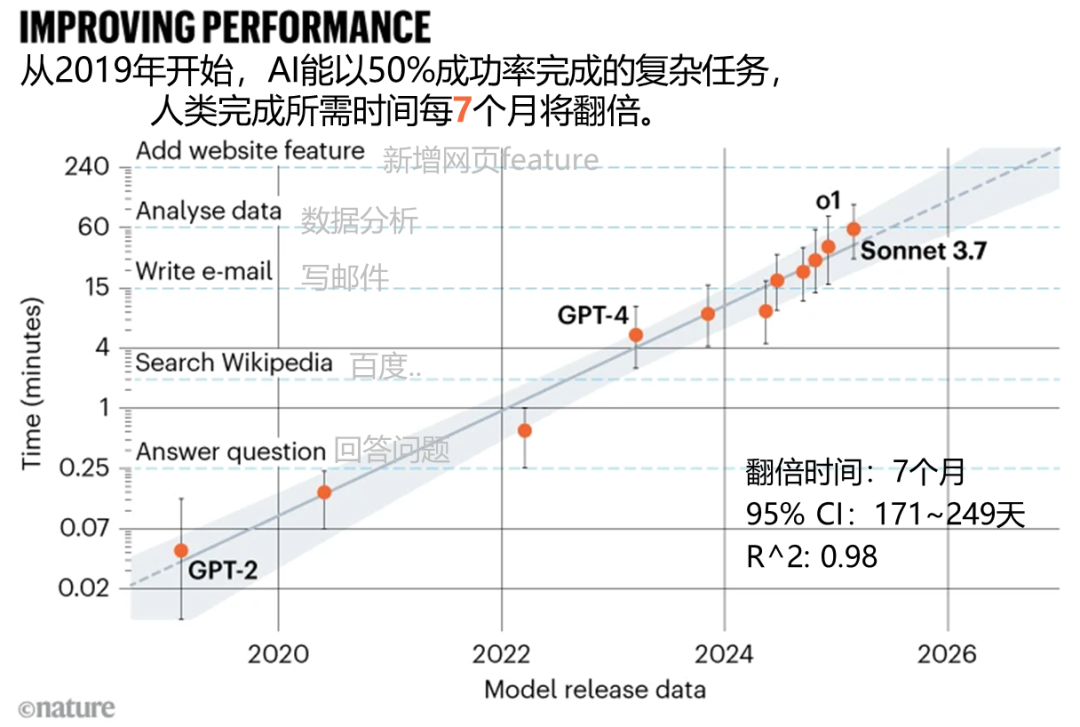
加州伯克利的这家非盈利研究机构METR,提出了一个新概念——“任务完成时间视界”。这个概念是用来评估AI工作能力的。它具体是指在成功率设定为50%的条件下,AI能完成的任务,人类专家平均需要多长时间来完成。简单来说,就是比较AI能承担的任务,人类需要多长时间才能完成。

研究验证的过程
METR团队设定了诸如复杂软件开发和机器学习研究等贴近实际的任务。他们记录了专业人士完成这些任务所需的真实时长,将其作为“人类基准”。随后,他们让13个2019年以后发布的AI模型执行这些任务,并利用回归分析绘制拟合曲线,计算出达到50%成功率的平均人类任务时长,这被称为“50%时间视界”。
早期模型的表现
2019年推出的GPT-2大型语言模型,在所有耗时超过一分钟的专家任务中均未成功。这说明那时的AI在处理具有一定难度和耗时的工作上,能力极为有限。它不能胜任稍微复杂和耗时的人类任务,暴露了早期AI技术的明显不足。

AI能力的快速提升
2023年之后的模型表现出色。例如,GPT-3、GPT-4 Turbo和o1等,其表现已经超越了研究预测的趋势线。这些模型的时间预测能力或许将从每212天翻倍提升至每90天翻倍。这一现象显示出,近年来人工智能技术的发展迅猛,解决复杂问题的能力显著增强。
未来趋势的预测
以目前的发展势头来看,METR研究团队预计,AI有望在2028年至2031年期间,以50%的准确率独立完成人类通常需要一个月才能完成的繁复工作。届时,AI在职场中的地位将变得更加突出。

大家对AI能否在规定时间内实现既定目标有信心吗?若觉得这篇文章对您有帮助,请别忘了点赞并转发!










