本期推荐的是一个开源的大数据分布式任务调度系统——Taier。

Taier 是一个分布式可视化的DAG任务调度系统。旨在降低ETL开发成本、提高大数据平台稳定性,大数据开发人员可以在 Taier 直接进行业务逻辑的开发,而不用关心任务错综复杂的依赖关系与底层的大数据平台的架构实现,将工作的重心更多地聚焦在业务之中。
功能特征
稳定性
- 单点故障:去中心化的分布式模式
- 高可用方式:Zookeeper
- 过载处理:分布式节点 + 两级存储策略 + 队列机制。每个节点都可以处理任务调度与提交;任务多时会优先缓存在内存队列,超出可配置的队列最大数量值后会全部落数据库;任务处理以队列方式消费,队列异步从数据库获取可执行实例
- 实战检验:得到数百家企业客户生产环境实战检验
易用性
- 支持大数据作业Spark、Flink的调度,
- 支持众多的任务类型,目前支持 Spark SQL、数据同步
后续将开源:SparkMR、PySpark、FlinkMR、Python、Shell、Jupyter、Tersorflow、Pytorch、HadoopMR、Kylin、Odps、
- SQL类任务(MySQL、PostgreSQL、Hive、Impala、Oracle、SQLServer、TiDB、greenplum、inceptor、kingbase、presto)
- 可视化工作流配置:支持封装工作流、支持单任务运行,不必封装工作流、支持拖拽模式绘制DAG
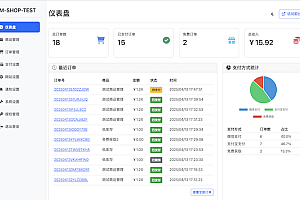
- DAG监控界面:运维中心、支持集群资源查看,了解当前集群资源的剩余情况、支持对调度队列中的任务批量停止、任务状态、任务类型、重试次数、任务运行机器、可视化变量等关键信息一目了然
- 调度时间配置:可视化配置
- 多集群连接:支持一套调度系统连接多套Hadoop集群
多版本引擎
- 支持Spark 、Flink等引擎的多个版本共存
Kerberos支持
- Spark
- Flink
系统参数
- 丰富,支持3种时间基准,且可以灵活设置输出格式
扩展性
- 设计之处就考虑分布式模式,目前支持整体 Taier 水平扩容方式
- 调度能力随集群线性增长
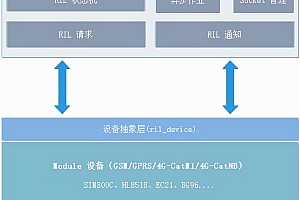
架构设计
- DatasourceX 是数据源插件,负责各类型数据源的元数据和数据操作,如获取表结构,预览表数据 等功能均由DatasourceX实现
- Chunjun 是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,比如MySQL,HDFS等,也可以采集实时变化的数据,比如MySQL binlog,Kafka等

主要界面





—END—
开源协议:Apache2.0