
尽管芯片巨头 Nvidia 往往会给人工智能世界蒙上一层阴影,但如果最新的基准测试结果有任何迹象的话,它简单地将竞争赶出市场的能力可能会增强。
周三,负责监督流行的机器学习性能测试 MLPerf 的行业联盟 MLCommons 发布了人工神经网络“训练”的最新数据。
烘焙比赛显示 Nvidia 在三年内拥有最少数量的竞争对手,只有一个:CPU 巨头英特尔。
在过去的几轮比赛中,包括 6 月份最近的几轮比赛,Nvidia 有两个或更多的竞争对手,包括英特尔、谷歌及其“张量处理单元”或 TPU 芯片,以及英国初创公司 Graphcore 的芯片。 在过去的几轮中,中国的电信巨头华为。
另外:英特尔推出新芯片,将为即将推出的 Aurora 超级计算机提供动力
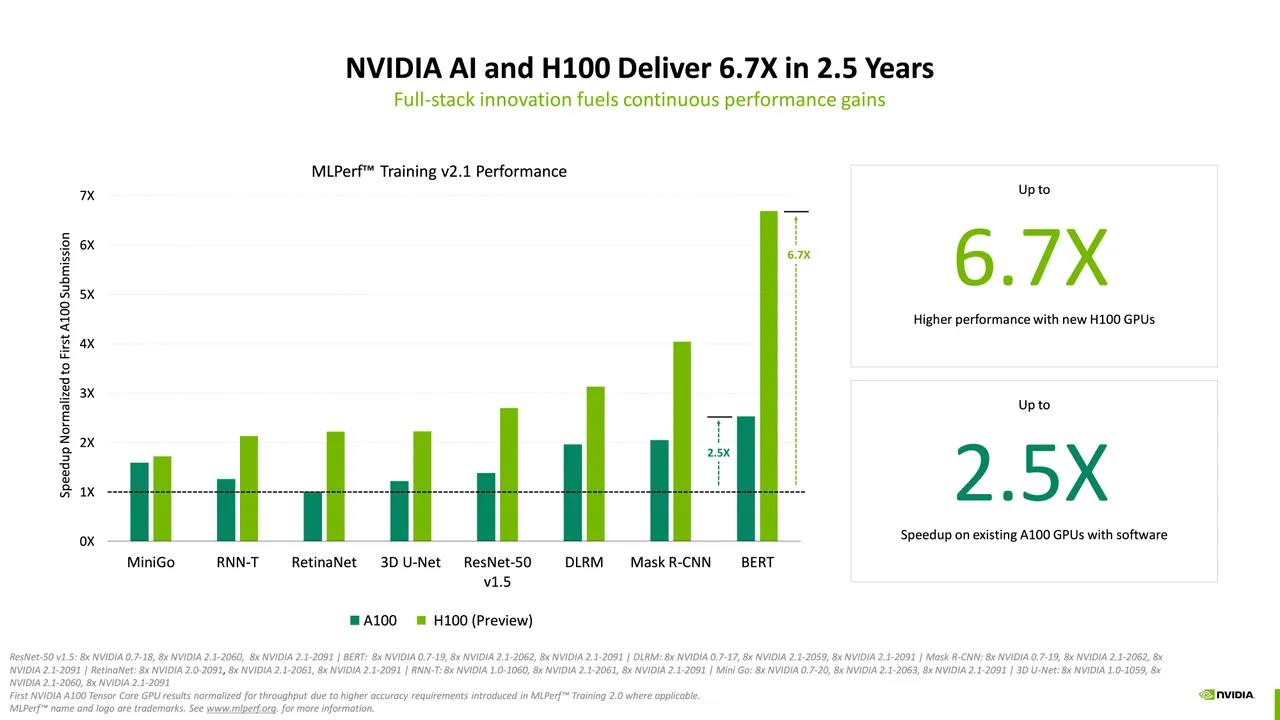
由于缺乏竞争,英伟达这次包揽了所有的最高分,而在 6 月份,该公司与谷歌并列第一。 Nvidia 提交的系统使用其已推出数年的 A100 GPU,以及为纪念计算先驱 Grace Hopper 而被称为“Hopper”GPU 的全新 H100。 H100 在所谓的推荐系统的八项基准测试之一中获得了最高分,这些推荐系统通常用于向 Web 上的人推荐产品。
英特尔提供了两个使用其 Habana Gaudi2 芯片的系统,以及标有“预览版”的系统,展示了其即将推出的代号为 Sapphire Rapids 的 Xeon 服务器芯片。
事实证明,Intel 系统比 Nvidia 部件慢得多。
Nvidia 在一份新闻稿中表示,“H100 GPU(又名 Hopper)在所有八个 MLPerf 企业工作负载中创造了训练模型的世界纪录。在首次提交 MLPerf 训练时,它们的性能比上一代 GPU 高出 6.7 倍。由 同样的比较,今天的 A100 GPU 多了 2.5 倍的肌肉,这要归功于软件的进步。”
在正式的新闻发布会上,Nvidia 的 AI 和云高级产品经理 Dave Salvator 重点介绍了 Hopper 的性能改进和对 A100 的软件调整。 Salvatore 展示了 Hopper 如何提高相对于 A100 的性能——换句话说,这是 Nvidia 对 Nvidia 的测试——还展示了 Hopper 如何能够同时超越 Intel Gaudi2 芯片和 Sapphire Rapids。
另外:Nvidia 首席执行官黄仁勋宣布“Hooper”GPU 可用性,大型 AI 语言模型的云服务
不同供应商的缺席本身并不代表一种趋势,因为在过去几轮 MLPerf 中,个别供应商决定跳过竞争,只是为了在随后的一轮中返回。
谷歌没有回应 ZDNET 的置评请求,说明它这次没有参与的原因。
在一封电子邮件中,Graphcore 告诉 ZDNET,该公司已经决定,与为 MLPerf 准备提交所需的数周或数月相比,目前可能有更好的地方可以投入工程师的时间。
“收益递减的问题出现了,”Graphcore 的通信主管 Iain Mackenzie 通过电子邮件告诉 ZDNET,“从某种意义上说,将不可避免地出现无限的跳跃式广告,进一步缩短时间,提出更大的系统配置 ”
Graphcore“可能会参与未来的 MLPerf 轮次,但目前它并没有反映我们看到最令人兴奋的进展的 AI 领域,”Mackenzie 告诉 ZDNET。 MLPerf 任务仅仅是“赌注”。
相反,他说,“我们真的想把精力集中在”“为人工智能从业者释放新能力”上。 为此,Mackenzie 说,Graphcore“您可以期待很快看到一些令人兴奋的进展”,“例如在模型稀疏化以及 GNN 方面,”或 Graph Neural Networks。
除了 Nvidia 的芯片在竞争中占据主导地位外,所有获得最高分的计算机系统都是 Nvidia 构建的,而不是来自合作伙伴的。 这也是与过去几轮基准测试相比的一个变化。 通常,某些供应商(例如戴尔)会因为使用 Nvidia 芯片组装的系统而获得最高分。 这一次,没有系统供应商能够在 Nvidia 自己使用其芯片方面击败 Nvidia。
MLPerf 训练基准测试报告调整神经“权重”或参数需要多少分钟,直到计算机程序在给定任务上达到所需的最低准确度,这个过程称为“训练”神经网络,其中 时间越短越好。
尽管最高分经常成为头条新闻——并且供应商向媒体强调——但实际上,MLPerf 结果包括各种各样的系统和广泛的分数,而不仅仅是一个最高分。
在电话交谈中,MLCommons 的执行董事 David Kanter 告诉 ZDNET 不要只关注最高分。 Kanter 表示,对于正在评估购买 AI 硬件的公司而言,基准套件的价值在于拥有一套范围广泛、规模各异、性能各异的系统。
提交的作品有数百个,从只有几个普通微处理器的机器到拥有数千个 AMD 主机处理器和数千个 Nvidia GPU 的机器,这些系统获得了最高分。
“谈到 ML 训练和推理时,对所有不同级别的性能都有各种各样的需求,”Kanter 告诉 ZDNET,“部分目标是提供可用于所有这些不同规模的性能度量 ”
坎特继续说道,“一些较小系统的信息与较大系统的信息一样有价值……所有这些系统都同样相关和重要,但可能对不同的人来说。”
至于这次没有 Graphcore 和谷歌的参与,坎特说,“我希望看到更多的提交,”他还补充说,“我理解对于许多公司来说,他们可能不得不选择如何投资工程资源…… .我想你会看到这些东西随着时间的推移在基准测试的不同轮次中潮起潮落。
Nvidia 缺乏竞争的一个有趣的次要影响意味着,某些训练任务的一些最高分不仅没有比之前的时间有所改善,而且还出现了倒退。
例如,在著名的 ImageNet 任务中,训练神经网络为数百万张图像分配分类器标签,这次的最高结果与 6 月份的第三名结果相同,这是一个 Nvidia 构建的系统 训练用时 19 秒。 6 月份的结果落后于谷歌“TPU”芯片的结果,后者的成绩仅为 11.5 秒和 14 秒。
当被问及重复早先提交的问题时,Nvidia 在电子邮件中告诉 ZDNET,这次它的重点是 H100 芯片,而不是 A100。 Nvidia 还指出,自 2018 年首次获得 A100 结果以来,已经取得了进展。在那轮训练基准测试中,一个八路 Nvidia 系统花了将近 40 分钟来训练 ResNet-50。 在本周的结果中,该时间已缩短到 30 分钟以下。
当被问及缺乏竞争性提交和 MLPerf 的可行性时,Nvidia 的 Salvatore 告诉记者,“这是一个公平的问题,”并补充说,“我们正在尽一切努力鼓励参与;行业基准因参与而蓬勃发展。我们希望随着 一些新的解决方案继续从其他人那里进入市场,他们希望在行业标准基准中展示这些解决方案的好处和优点,而不是提供他们自己的一次性性能声明,这非常困难 核实。”
Salvatore 说,MLPerf 的一个关键要素是严格发布测试设置和代码,以确保测试结果在来自数十家公司的数百份提交中保持清晰和一致。
除了 MLPerf 培训基准分数外,MLCommons 周三发布的还提供了 HPC、科学计算和超级计算机的测试结果。 这些提交的内容包括来自 Nvidia 和合作伙伴的混合系统,以及运行自己芯片的富士通 Fugaku 超级计算机。
第三个竞赛名为 TinyML,衡量低功耗和嵌入式芯片在执行推理时的表现,推理是机器学习的一部分,训练有素的神经网络在其中进行预测。
Nvidia 迄今尚未参加的这场比赛有有趣的芯片和供应商提交的多样性,例如芯片制造商 Silicon Labs 和高通、欧洲技术巨头 STMicroelectronics 以及初创公司 OctoML、Syntiant 和 GreenWaves Technologies。
在 TinyML 的一项测试中,一项使用 CIFAR 数据集和 ResNet 神经网络的图像识别测试,GreenWaves(总部位于法国格勒诺布尔)因处理数据的延迟最低并提出了 预言。 该公司提交了其与 RISC 处理器相结合的 Gap9 AI 加速器。
在准备好的评论中,GreenWaves 表示,Gap9“在中等复杂度的神经网络(例如 MobileNet 系列)的分类和检测任务中以及在复杂的混合精度递归神经网络(例如我们基于 LSTM 的音频)上提供了极低的能耗 降噪器。”








