
人工智能中极其流行的深度学习部分令人担忧的方面之一是程序的规模越来越大。 该领域的专家表示,计算任务注定会变得越来越大,因为规模很重要。
越来越大的项目是资源大户,这是深度学习社会伦理中的一个重要问题,这一困境引起了《自然》等主流科学期刊的关注。
这就是为什么每次提到效率这个词都很有趣,比如,我们能让这个人工智能程序更有效率吗?
DeepMind 和谷歌大脑部门的科学家最近对他们去年推出的神经网络 Perceiver 进行了改造,以使其在计算能力需求方面更加高效。
新程序 Perceiver AR 以越来越多的深度学习程序的“自回归”方面命名。 自回归是一种让机器将其输出用作程序新输入的技术,这是一种递归操作,可形成多个元素如何相互关联的注意力图。
谷歌于 2017 年推出的广受欢迎的神经网络 Transformer 具有这种自回归特性。 许多模型都这样做了,包括 GPT-3 和 Perceiver 的第一个版本。
Perceiver AR 是 Perceiver 的第二个版本,称为 Perceiver IO,于 3 月推出,而原始 Perceiver 于一年前的本月推出。
原始感知器的创新之处在于,将 Transformer 进行微调,让它以灵活的形式消费各种输入,包括文本声音和图像,而不是局限于特定的一种输入,将各种不同的输入分开。 通常开发神经网络。
Perceiver 是越来越多的程序之一,它们使用自动回归注意机制来混合不同的输入模式和不同的任务域。 其他示例包括 Google 的 Pathways、DeepMind 的 Gato 和 Meta 的 data2vec。
然后,在 3 月,构建 Perceiver 的 Andrew Jaegle 及其同事的同一个团队推出了“IO”版本,它增强了 Perceiver 的输出以适应不仅仅是分类,实现了具有各种结构的大量输出,范围从 文本语言输出到光流场到视听序列到符号无序集。 它甚至可以在星际争霸II游戏中产生运动。
现在,在使用 Perceiver AR 进行通用、长上下文自回归建模的论文中,Jaegle 和团队面临的问题是,随着模型在多模式输入和输出任务中变得越来越雄心勃勃,它们应该如何扩展。
问题是,Transformer 的自回归质量,以及任何其他构建从输入到输出的注意力图的程序,都需要在数十万个元素的分布方面具有巨大的规模。
这就是注意力的致命弱点,准确地说,需要关注任何事情,以便组装形成注意力图的概率分布。
正如 Jaegle 和团队所说,随着输入中必须相互比较的事物数量的增加,它变成了计算方面的扩展噩梦:
这种长格式的上下文结构与 Transformer 的计算特性之间存在张力。 Transformers 反复对其输入应用自注意力操作:这导致计算要求同时随输入长度呈二次方增长并随模型深度呈线性增长。 随着输入数据的增长,需要更多的输入标记来观察它,并且随着输入数据中的模式变得更加微妙和复杂,需要更多的深度来对产生的模式进行建模。 计算限制迫使 Transformers 的用户截断模型的输入(防止它观察多种远程模式)或限制模型的深度(剥夺它对复杂模式建模所需的表达能力)。
事实上,最初的 Perceiver 通过对输入的潜在表示进行关注而不是直接关注,从而提高了 Transformers 的效率。 这具有“[解耦]处理大型输入数组的计算要求与使网络非常深入所需的计算要求的效果。”
输入表示被压缩的潜在部分成为一种更有效的注意力引擎,因此,“对于深度网络,自注意力堆栈是大量计算发生的地方”,而不是对无数输入进行操作。
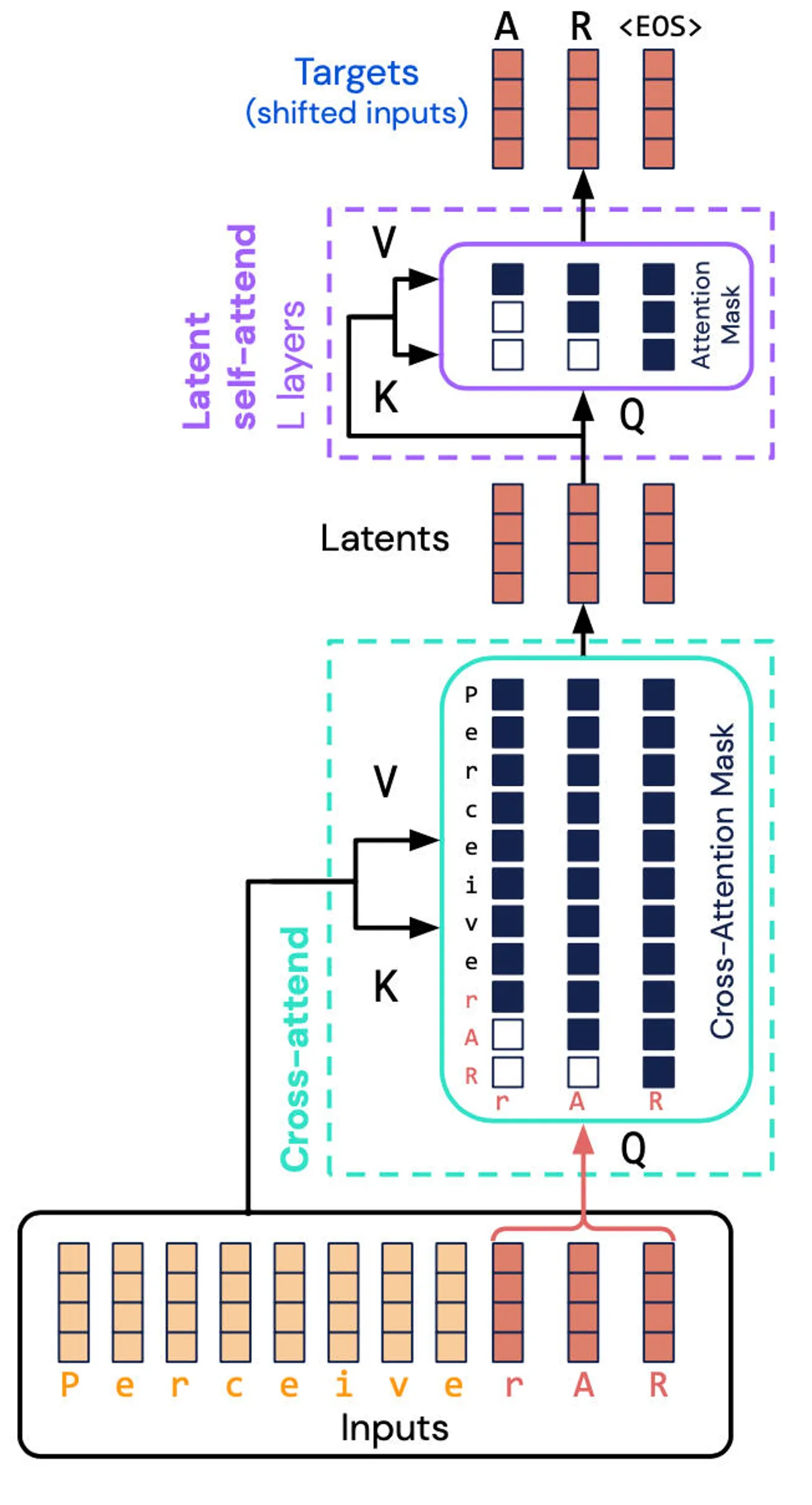
但挑战仍然存在,即 Perceiver 无法像 Transformer 那样生成输出,因为这种潜在表示没有秩序感,而秩序在自回归中是必不可少的。 每个输出都应该是它之前而不是之后的产物。
“然而,由于每个模型都潜在地关注所有输入,而不管位置如何,感知器不能直接用于自回归生成,这要求每个模型输出仅依赖于按顺序排列在它之前的输入,”他们写道。
借助 Perceiver AR,该团队更进一步,将命令插入 Perceiver,使其具备自动回归功能。
关键是所谓的输入的“因果掩蔽”,其中发生“交叉注意力”和潜在表示,以迫使程序只关注给定符号之前的事物。这种方法恢复了方向性质量 Transformer,但计算量要少得多。
结果是能够在更多输入上完成 Transformer 所做的工作,但性能显着提高。
“Perceiver AR 可以学习在合成复制任务中完美识别至少 100k 令牌距离的长上下文模式,”他们写道,而 Transformer 的硬性限制为 2,048 个令牌,其中更多令牌等于更长的上下文,这应该等于 程序的输出更复杂。
Perceiver AR 通过“与广泛使用的仅解码器 Transformer 和 Transformer-XL 架构相比提高了效率,并且能够改变测试时使用的计算以匹配目标预算。”
具体来说,他们写道,对于相同数量的注意力,计算 Perceiver AR 的挂钟时间显着减少,并且能够在相同的计算预算下获得更大的上下文——更多的输入符号:
Transformer 的上下文长度限制为 2,048 个标记,即使只有 6 层——更大的模型和更大的上下文长度需要太多内存。 使用相同的 6 层配置,我们可以将 Transformer-XL 内存扩展到 8,192 的总上下文长度。 Perceiver AR 可扩展到 65k 上下文长度,并且可以通过进一步优化扩展到超过 100k 上下文。
所有这些都意味着计算的灵活性:“这使我们能够更好地控制在测试时用于给定模型的计算量,并允许我们顺利地权衡速度与性能。”
Jaegle 和他的同事写道,这种方法可以用于任何输入类型,而不仅仅是文字符号,例如图像的像素:
只要应用了掩码,就可以将相同的过程应用于可以排序的任何输入。 例如,图像的 RGB 通道可以按光栅扫描顺序排序,通过解码序列中每个像素的 R、G 和 B 颜色通道,甚至在不同的排列下。
作者看到了 Perceiver 的巨大潜力,写道“Perceiver AR 是通用、长上下文自回归模型的一个很好的候选者。”
但是,在计算机效率因素中还有一个额外的波动。 作者指出,最近的一些努力试图通过使用“稀疏性”来减少自动回归注意力的计算预算,这是限制哪些输入元素被赋予重要性的过程。
这有一些缺点,主要是太死板了。 “使用稀疏性的方法的缺点是,这种稀疏性必须手动调整或使用通常特定于领域且难以调整的启发式方法创建,”他们写道。 这包括 OpenAI 和英伟达 2019 年的“稀疏变压器”等努力。
“相比之下,我们的工作并没有在注意力层上强制采用手工制作的稀疏模式,而是让网络了解哪些长上下文输入需要注意并通过网络传播,”他们写道。
“最初的交叉参与操作减少了序列中的位置数量,可以被视为一种学习稀疏性的形式,”他们补充道。
以这种方式学习的稀疏性本身可能会成为未来几年深度学习模型工具包中的一个强大工具。









