
根据 MLCommons 周三发布的数据,谷歌和英伟达在每年两次的人工智能程序培训基准测试中并列得分最高。
2.0 版 MLPerf 训练结果显示,谷歌在商业系统的四项任务上训练神经网络的时间最少,得分最高:图像识别、对象检测、一项针对小图像的测试和一项针对大图像的测试, 和 BERT 自然语言处理模型。
Nvidia 在八项测试中的其他四项测试中获得了最高荣誉,这是因为其商用系统:图像分割、语音识别、推荐系统,以及解决在“迷你围棋”数据集上玩围棋的强化学习任务。
两家公司在多项基准测试中都取得了高分,但是,谷歌没有报告其他四项测试的商用系统的结果,只报告了它赢得的那四项测试。 Nvidia 报告了所有八项测试的结果。
基准测试报告调整神经“权重”或参数需要多少分钟,直到计算机程序在给定任务上达到所需的最低准确度,这一过程称为“训练”神经网络。
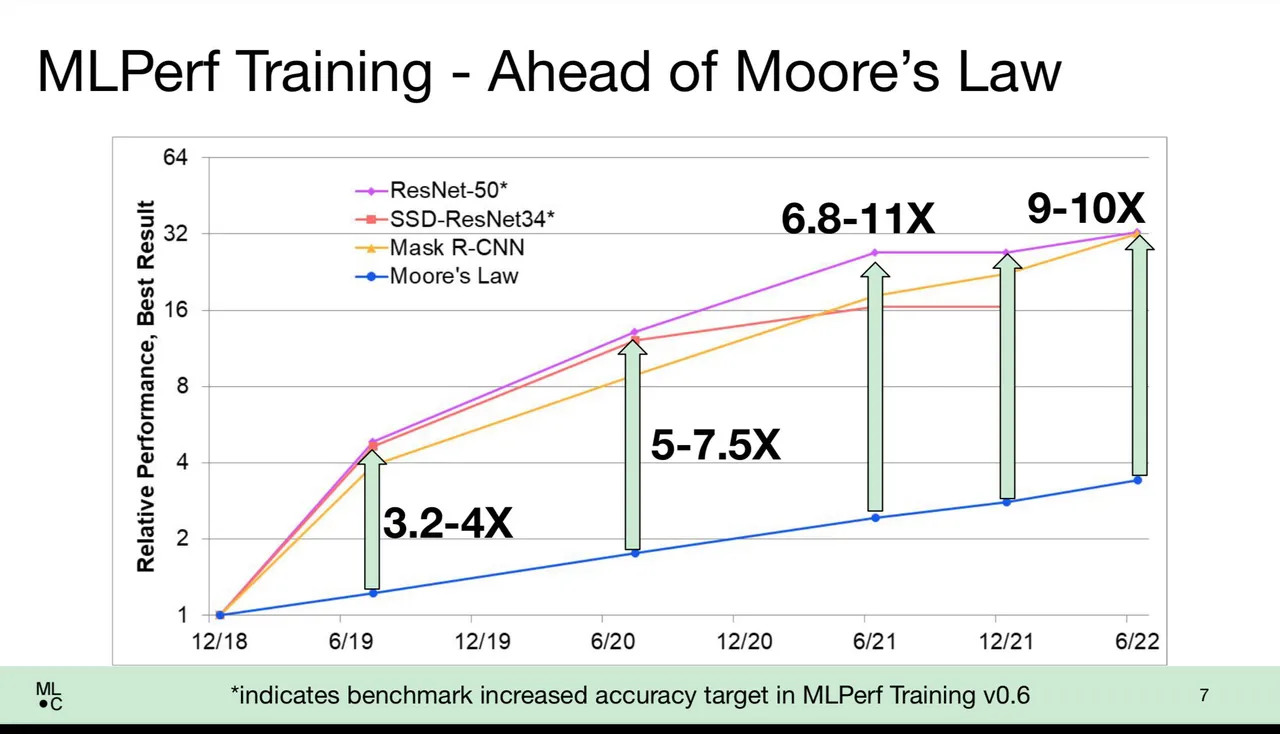
在所有供应商中,由于更强大的功能和更智能的软件方法,培训时间显着缩短。 在媒体简报会上,MLCommons 的执行董事 David Kanter 解释说,从广义上讲,结果表明训练的性能提高优于摩尔定律,传统的经验法则表示芯片的晶体管速度每 18 到 24 个月翻一番 提高计算机性能。
Kanter 说,例如,在著名的 ImageNet 任务中,训练神经网络为数百万张图像分配分类器标签,如今的得分比简单的芯片改进所暗示的要快 9 到 10 倍。
“我们做得比摩尔定律好很多,”坎特说。 “假设晶体管与性能呈线性关系,你会期望获得大约三倍半的性能;事实证明,我们得到了 10 倍的摩尔定律。”
Kanter 说,“普通的男人或女人”会从中获益,“只有一个工作站的研究人员”只包含 8 个芯片,他说。
Nvidia 在构成世界上大部分 AI 计算的 GPU 芯片的销售中占据主导地位,它会定期提交大部分或所有测试的结果。 他指出,那些单一的工作站正在看到改进或 4 到 8 倍的简单晶体管缩放。 “我们正在将更多的能力交到研究人员手中,这使我们能够进行更多的实验,并有望做出更多的发现。”
谷歌的 TPU 是 Nvidia 芯片的主要竞争对手之一,它与 MLPerf 的往绩记录要差得多。 在 12 月的基准测试报告中,该公司仅提交了一个测试编号,用于在 BERT 测试中使用其 TPU 进行实验。
谷歌在准备好的评论中表示,“谷歌的 TPU v4 [第 4 版] ML 超级计算机在五个基准测试中创造了性能记录,平均速度比下一个最快的非谷歌提交的速度快 1.42 倍,比我们的 MLPerf 1.0 提交速度快 1.5 倍。”
在 ZDNet 询问谷歌为什么选择与这四个类别的商业系统竞争而不是其他四个类别时,该公司在一封电子邮件回复中表示,“我们提交的目的是主要关注能够为我们带来 MLPerf 之外的最大利益的工作负载。
“我们根据模型与谷歌内部和谷歌云客户使用的 ML 模型的相似性来决定提交哪些模型。提交和调整基准是一项重要的工作,因此我们集中精力为我们最大限度地提高 MLPerf 之外的利益。
“鉴于此,我们将精力集中在云可用类别的四个基准测试上——BERT、ResNet、RetinaNet、MaskRCNN。”
Nvidia 强调了其自身以及包括戴尔和联想在内的合作伙伴提交的全面范围。 使用一种或另一种 Nvidia 芯片的计算机负责 105 个系统和 264 个报告结果中的 235 个报告测试结果。
“根据今天发布的 MLPerf 基准测试,NVIDIA 及其合作伙伴继续在所有基准测试中提供最佳的整体 AI 训练性能和最多的提交,其中 90% 的所有条目来自生态系统,”Nvidia 执行官 Shar Narasimhan 在准备好的评论中说。
“NVIDIA AI 平台涵盖了 MLPerf Training 2.0 回合的所有八项基准测试,突出了其领先的多功能性。”
在一张幻灯片中,Narasimhan 展示了他所说的“标准化”测量,该测量试图实现每个加速器的性能,因为不同的机器提交使用不同数量的加速器芯片。 Narasimhan 说,这项措施表明 Nvidia 在 8 项测试中的 6 项中表现最佳。
Narasimhan 说:“我们认为,这种将最高性能标准化为 1.0 X,然后以相似规模显示所有剩余加速器进行比较的特殊方法是比较所有人的最公平方式。”
在其他发展中,MLPerf 测试继续获得追随者,并获得了比过去更多的测试结果。 共有 21 个组织报告了 264 个测试结果,高于 12 月 1.1 版报告中的 14 个组织和 181 个报告的提交。
新进入者包括华硕; 中国科学院,或 CASIA; 计算机制造商 H3C; HazyResearch,一个研究生提交的名字; Krai,曾参加过其他MLPerf竞赛,推理,但从未参加过训练; 并启动 MosaicML。
在前五名的商业系统中,Nvidia 和谷歌紧随其后的是少数几个成功获得第三、第四或第五名的提交者。
微软的 Azure 云单元在图像分割比赛中获得第二名,在高分辨率图像的目标检测比赛中获得第四名,在语音识别比赛中获得第三名,所有系统均采用 AMD EPYC 处理器和 Nvidia GPU。
计算机制造商 H3C 在图像分割竞赛、高分辨率图像对象检测竞赛、推荐引擎和围棋游戏等四项测试中获得第五名,并且在语音识别方面也获得了第四名。 所有这些系统都使用了 Intel XEON 处理器和 Nvidia GPU。
Dell Technologies 在使用低分辨率图像的对象检测中排名第四,在 BERT 自然语言测试中排名第五,两者均使用 AMD 处理器和 Nvidia GPU 的系统。
计算机制造商 Inspur 凭借使用 AMD EPYC 处理器和 Nvidia GPU 的系统在语音识别方面排名第五,在推荐系统方面排名第三和第四,分别使用基于 XEON 和基于 EPYC 的系统。
Graphcore 是一家总部位于英国布里斯托尔的初创公司,它使用替代芯片和软件方法构建计算机,在 ImageNet 中排名第五。 IT 解决方案提供商 Nettrix 在图像分割比赛中获得第四名,在围棋强化学习挑战赛中获得第四名。
在为记者做的简报中,Graphcore 强调其能够以更低的价格为其配备不同数量 IPU 加速器芯片的 BowPOD 机器提供与 Nvidia 相比具有竞争力的分数。 例如,该公司吹捧其 BowPOD256,它在 ResNet 图像识别中获得第五名,比 8 路 Nvidia DGX 系统快十倍,同时成本更低。
“最重要的肯定是经济性,”Graphcore 的软件主管马特·菲尔斯 (Matt Fyles) 在媒体简报会上说。 “我们过去有一种趋势,即机器速度越来越快,但价格越来越贵,但我们已经划定了界限,我们不会让它变得更贵。”
尽管一些较小的 Graphcore 机器在几分钟的训练时间上落后于最好的分数或 Nvidia 和 Graphcore,“我们的客户都不关心几分钟,他们关心的是你是否有竞争力,然后你可以解决 他们关心的问题,”他说。
Fyles 补充说,“有很多项目有数千个芯片,但现在行业将扩展您可以使用该平台做的其他事情,而不仅仅是,我们必须赢得这场基准竞赛——这是逐底竞争 ”
与过去的报道一样,Advanced Micro Devices 对 Intel 拥有吹嘘的权利。 在参赛的 130 个系统中,有 79 个使用了 AMD 的 EPYC(霄龙)或 ROME 服务器处理器,这一比例高于英特尔至强芯片。 此外,八项基准测试的前 40 个结果中有 33 个是基于 AMD 的系统。
与过去一样,英特尔除了在合作伙伴系统中配备 XEON 处理器外,还通过其 Habana Labs 单元推出了自己的参赛作品,使用 XEON 和 Habana Gaudi 加速器芯片而不是 Nvidia GPU。 英特尔仅将精力放在 BERT 自然语言测试上,但未能进入前五名。
八项基准测试中有七项与 12 月的比赛相同。 一个新条目是对其中一项对象检测任务的替代,在该任务中,计算机必须在图片中勾勒出一个对象的轮廓,并在轮廓上附加一个标签来识别该对象。
在这个新版本中,广泛使用的 COCO 数据集和 SSD 神经网络被新的数据集 OpenImages 和新的神经网络 RetinaNet 所取代。
OpenImages 使用大于 1,200 x 1,600 像素的图像文件。 另一个目标检测任务仍然使用 COCO,它使用分辨率较低的 640 x 480 像素图像。
在媒体发布会上,MLCommons 的 Kanter 解释说,OpenImages 数据集结合了一个新的基准神经网络供提交者使用。 先前的网络基于经典的 ResNet 神经网络,用于图像识别和图像分割。
新测试中使用的替代方法称为 RetinaNet,它通过对 ResNet 结构进行多项增强来提高准确性。 例如,它添加了所谓的“特征金字塔”,它会同时查看网络所有层中对象周围上下文的所有外观,而不仅仅是网络的一层,这会添加上下文以更好地实现 分类。
“特征金字塔是经典计算机视觉的一项技术,因此在某种程度上,这是对应用于神经网络领域的经典方法的重复,”坎特说。
除了特征金字塔之外,RetinaNet 的底层架构,称为 ResNeXt,通过 ResNet 上的一项新创新来处理卷积。 经典 ResNet 使用所谓的“密集卷积”通过图像的高度和宽度以及 RGB 通道过滤像素。 ResNeXt 将 RGB 过滤器分解为单独的过滤器,称为“分组卷积”。 这些小组并行运作,学习专门研究颜色通道的各个方面。 这也有助于提高准确性。








