
对人工智能机器学习类别的近期文献调查显示,自动生成诗歌的技术发展稳步推进。
输出仍然相当平庸,但它已经足够好了,一些人类读者会在受控评估中给诗歌打出可观的分数。 有些人甚至会被愚弄,将人类作者归于机器诗歌。
虽然最崇高的人类写作形式的本质逃避了人工智能,但该软件足够熟练,可以生成可以通过测试的传真。
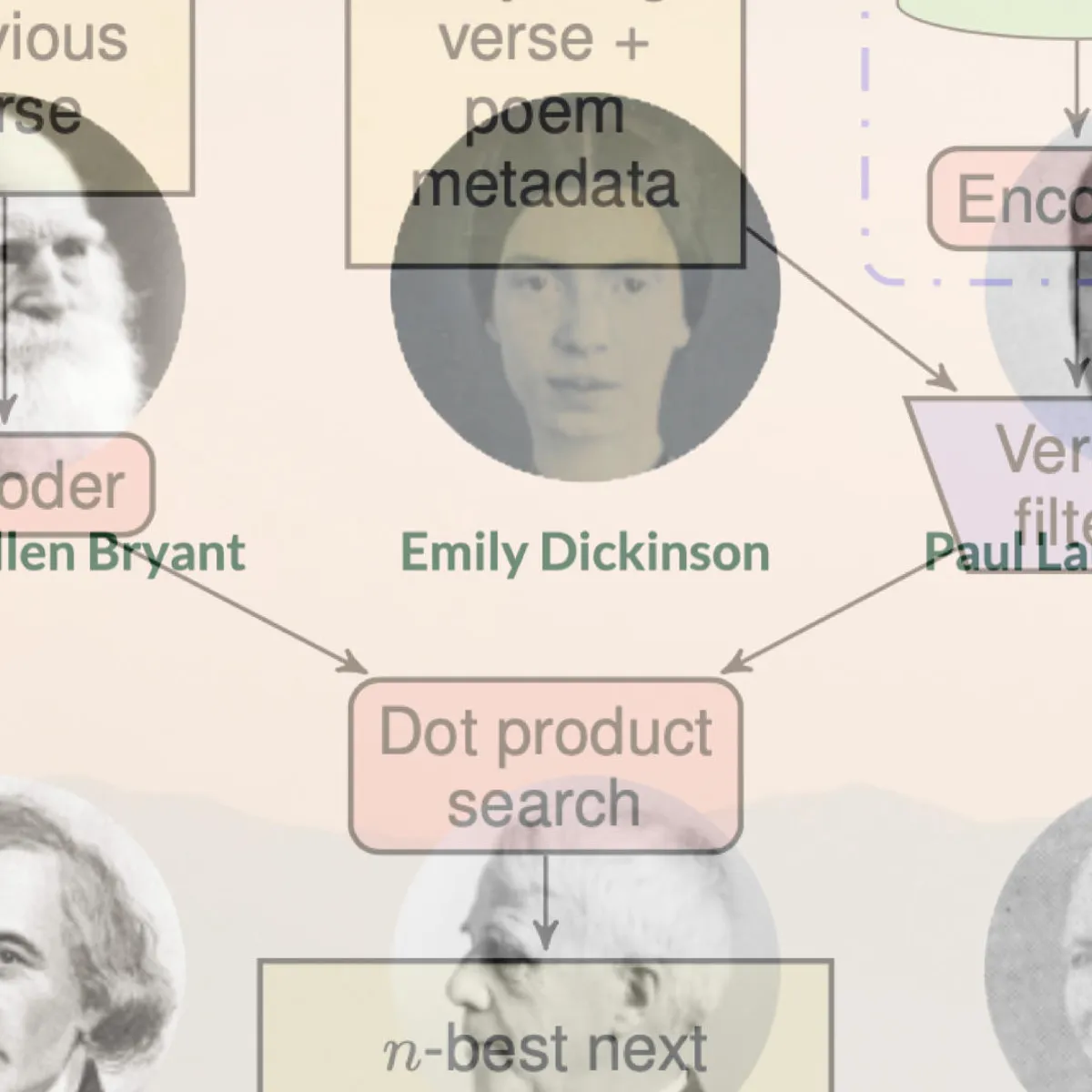
本文顶部列出的这首诗部分是由机器创作的。 谷歌软件程序,名为 Verse by Verse,于 3 月推出,从人类那里获取一段输入,即文本的第一行,她的眼睛,双池神秘的光。 然后它继续该节,自动产生随后的三行。
这首绝句,正如它所说的那样,受到众包工作者的青睐,谷歌招募他们将人机加机器的创作与完全由人类创作的诗歌进行比较。 该计划和评估在谷歌研究人员 David Uthus、Maria Voitovich 和 R.J. 的介绍性论文中进行了描述。 米卡尔。
Verse by Verse 生成文本的能力是该程序吸收了 22 位不同诗人作品的语料库的结果。 在程序的网站上,用户被邀请选择最多三位著名诗人作为“缪斯”来完成一首诗,用户提供第一行。
结果是一场有趣的室内游戏和一首糟糕的诗。 以下是当 Rainer Maria Rilke 的 Duino Elegies 的第一行被逐句输入时会发生什么:
四行输出要求用户从算法生成的多行建议行中进行选择,每行都符合所选择的三位诗人之一的脉络。 虽然其他一些组合可能更可取——选择和可能性是自动文本的标志性元素——但即使经过多次尝试,也不太可能出现任何开创性的诗句。
Verse by Verse 是过去十年学术界 AI 学者以及谷歌和其他大公司的研究人员之间趋势的一个例子,以改进机器学习程序,这些程序要么生成全新的作品,要么扩展一个人输入的短语。
这些作品都利用了所谓的语言模型,这些程序使用机器学习来构建单词通常如何组合成一个句子的统计表示。 范式语言模型是 GPT-3,这是去年由旧金山初创公司 OpenAI 发布的程序,风靡全球。
许多评论员完全被 GPT-3 看似人性化的文本所吸引。 《纽约客》的 Stephan Marche 曾写道,GPT-3 可以像 Franz Kafka 一样写作,并引用了 GPT-3 重写的《变形记》(The Metamorphosis) 的片段。
事实上,redux 听起来真的不像原来的那样。 但是 Marche 和其他人已经抓住了 GPT-3 和其他语言模型的主要成就,即复制单词组合的表面质量,其中可以包括文体模拟。
诗歌一直是推动此类语言模型可以捕捉的极限的流行选择,因为大多数诗歌都以可以统计测量的形式质量为标志,包括韵律、押韵方案和谐音。
最近关于 AI 诗歌的工作试图以越来越严格的方式模仿这些形式元素。
U.C. 的 Kevin Yang 和 Dan Klein 伯克利在 4 月发表了一篇关于他们发明的论文,名为 FUDGE,它可以自动生成莎士比亚对句的第二行,自发地复制抑扬格五音步,这是莎士比亚非常有效地利用的重音模式。
出现的是笨重的对联,但体面的形式主义。 这是莎士比亚的十四行诗第 48 首原作:
我走的时候多么小心,
每一件小事都在最真实的酒吧下进行推力,
对我来说它可能未被使用
从谎言之手,在可靠的信任病房!
但是你,我的珠宝琐事是给你的,
最值得安慰,现在是我最大的悲伤,
你最亲爱的,我只关心,
艺术留下了每一个庸俗小偷的猎物。
我没有把你锁在任何箱子里,
除了你不在的地方,虽然我觉得你在,
在我胸膛的温柔闭合中,
你可以随意从哪里来和分开;
我担心你会被偷走,
因为事实证明,对于如此宝贵的奖品来说,事实证明是偷窃。
在 FUDGE 中,Yang 和 Klein 取下了结尾对联的第一行,我担心即使从那里你也会被偷走,并让程序写下新的第二行。 结果并不那么富有诗意,也没有十四行诗扩展隐喻的痕迹:
甚至你会被偷走,我担心,
因为这就是结局。 这很清楚。
从技术上讲,FUDGE 是一项杰作。 Yang 和 Klein 从 2019 年开始采用 GPT-3 的前身 GPT-2 并对其进行了调整。 (GPT-2 可供下载,这使其成为语言模型开发的热门选择,不像 GPT-3,其使用受到 OpenAI 的限制。)
GPT-2 和 GPT-3 对抑扬格五音步一无所知,它们只是模仿给定的任何示例风格。 通过添加几行代码,Yang 和 Klein 能够强制 FUDGE 可靠地保持抑扬格。 因此,FUDGE 对联以一致的方式履行了文体义务。
值得赞扬的是,杨和克莱因对生成的对联的质量没有抱任何幻想。 “莎士比亚只是作为一个异想天开的参考点,”他们写道,“我们这一代人显然不喜欢莎士比亚的原作。”
当机器诗表现平平时,在一个非常特殊的形式传统中它会更加明显。 以打油诗为例,这些深受喜爱的五行诗具有一致的音节排列和一致的押韵方案。
巨蟒剧团成名的迈克尔佩林提供了他自己创作的打油诗:
他们说一个叫保拉的助产士,
如果有什么麻烦就给她打电话。
她在水中的技能
她从搬运工那里学到
谁从拖网渔船上运送新鲜的鱼。
不管这些诗是否有趣,以及它们通常被认为是有趣的,它们通常有一个完整的想法,在五行中表现出来,带有一种旨在产生喜悦的转折或令人惊讶的转折。
为了尝试自动生成打油诗,Jianyou Wang 和杜克大学的同事在 3 月份推出了 LimGen。 LimGen 使用所谓的模板,一组打油诗线条形成的规则,例如主语加动词加宾语。 这是基于 300 个打油诗作为例子,一个相对较小的选择。
Wang 和团队在模板中添加了另一种在语言模型中很流行的算法,称为集束搜索。 它自动对模板程序生成的文本进行评分,以选择最佳输出,作为一种投票权。
从某种意义上说,结果让人想起打油诗,但它们有些平淡:
有一个诚实的人叫德怀特
谁在战斗中失去了所有的钱。
他的朋友们很伤心,
他们愿意打赌,
他们不喜欢被恶意对待的感觉。
有一个叫雅克的大声女服务员,
谁把她所有的咖啡都倒了。
但就在她动容的那一刻,
她被一只鸟击中,
然后她看到它飞向湖边。
尽管这些打油诗大体上具有连续性,但在每一节的结尾都有一种奇怪的分解,仿佛思想的发展已经屈服于形式上的限制。
鉴于原始输出的结果不尽如人意,更多程序可能会效仿 Google 在 Verse by Verse 中的人工协作。
在 AI 中,这种联合努力的常用术语是“人在环路”。 出现的一个引人注目的倒置是“计算机在环”。
来自伊斯坦布尔 Koç ̧ 大学和马尔马拉大学的学者 Imke van Heerden 和 Anil Bas 在 3 月推出了一种计算机在环方法,以招募人类有效地将机器生成的文本编辑成一首诗。 他们专注于南非荷兰语,这是南非和该地区其他国家/地区的官方语言之一,这种语言传统上在 AI 语言模型中并未受到太多关注。
Van Heerden 和 Bas 的语言模型程序,称为 AfriKI,用于“Afrikaanse Kunsmatige Intelligensie”,南非荷兰语人工智能,明确地试图增强而不是取代人类的工作。
“虽然 [自然语言生成] 在寻求完全自动化的过程中可能不赞成人类的参与,但我们以人为本的框架却恰恰相反,”他们写道。
“这项研究表明,人机协作可以增强人类的创造力。”
AfriKI 吸收了 Etienne van Heerden 的一部南非荷兰语小说 Die Biblioteek aan die Einde van die Wêreld(世界尽头的图书馆)的全部 208,616 个单词。
在一个看起来类似于谷歌的 Verse by Verse 的过程中,AfriKI 生成了数百个散文短语,并且人类选择使用哪些短语,以及将它们组合成一个节的顺序。
结果是一些短片具有一些生动的意象和一些有趣的隐喻用法:
Die konstabel se skiereiland
非洲饮料
onheil 在死水中。
Die landskap kantel sy 地毯
在 sigbewaking en vlam 中。
Ons oopgesnyde清酒
brandtrappe vir die ander 状态。
Hierdie grond 词 intimidasie。
警员的半岛
非洲饮品
水中的灾难。
风景向后倾斜
在监视和火焰中。
我们切开的事
其他州的防火梯。
这种土壤变得令人生畏。
正如作者所指出的,这里有足够多的比喻语言和隐喻,让人想起一些诗歌流派。 “这种语言可以被描述为极简主义、令人回味和抽象,因此易于解释,类似于意象派和超现实主义诗歌。”
在一定程度上。 诗词仍似多染色彩,笔触,无意。
很容易看出所有语言模型都会陷入的共同陷阱。 机器学习程序是转换机器:它们的用途是以自动化方式将一些输入数据转换为输出。
语言模型将示例文本(例如诗歌)转换为一个分数,该分数总结了单词在共现频率方面的相关性,以及许多其他可测量的事物,例如声音频率和音节数。
通过这种方式,AI 正在执行数据压缩操作,将整个图书馆压缩成经济的统计数据包。 解压缩的行为在生成的文本中重构语言的形式模式。
逃脱这样一个过程的是另一种压缩,人类诗人在更大规模上对联想的压缩。 诗歌在事物的边缘玩耍,没有说出的是能够由此浮现的东西。
这是罗密欧与朱丽叶通过文字游戏互相浪漫的故事:
罗密欧:如果我用我最卑鄙的手亵渎
这神圣的神殿,温柔的罪就是这
我的嘴唇,两个脸红的朝圣者,准备好了
用温柔的吻抚平那粗糙的触感
朱丽叶:善良的朝圣者,你的手太过分了,
这表明了礼貌的奉献;
因为圣徒的手是朝圣者的手所触及的,
手掌对手掌是神圣的帕默之吻。
线条在内部结构中不仅包含声像的形式关系。 它们还包含翻转想法的游戏,从不同的角度看待它们,像光一样折射它们。
是否可以在统计模型(也许是更复杂的模型)中捕捉到这一点,是一个有趣的问题。 但是现在,人工智能的最先进技术并没有抓住要点。
赠品是 AI 研究人员谈论他们的努力的方式。 正如一篇论文所说,各种语言算法都在研究“诗歌生成的问题”。 但世代可能是错误的术语。
在他写给年轻诗人的信中,里尔克写到孤独的重要性,因为它可以剥离世界的事务,明确什么是必不可少的。
再想想里尔克杜伊诺挽歌的第一行:
Wer, wenn ich schriee, hörte mich denn aus der Engel Ordnungen?
如果我哭了,谁会在天使等级中听到我的声音?
小说家威廉·加斯 (William Gass) 曾说过,里尔克 (Rilke) 与其说是创作了挽歌,不如说是接受了挽歌。
“Duino 挽歌不是写出来的,”William Gass 观察到,“他们被等待着”,正如评论家 Lewis Hyde 引用他的话。 (加斯自己说,他对写作形式品质的关注是一个婴儿期,一个障碍。“直到我准备好走出形式化阶段,我才开始阅读里尔克,”他说。)
人类诗人,与其说是一台转换机器,不如说更像是一根经过微调的天线,接收已经存在的东西。 里尔克提到的孤独允许那种关注。
人工智能,作为一台转化机器,在孤独、安静、寂静的相反方向上运行。 人工智能在某种意义上害怕真空。 它的目标是重构全部信息,即大数据。 通常情况下,自动语言会情不自禁地添加更多内容。
一些人工智能研究公开承认仅仅复制形式特征的缺点。 IBM 研究人员在 2018 年开展的一项名为 Deep-Speare 的研究要求人群工作者判断莎士比亚的十四行诗是否真的出自 The Bard 还是机器生成的。
虽然机器创作的许多诗歌在形式上——比如押韵和韵律——被认为是成功的,但人类群众工作者发现诗歌在情感影响方面不令人满意。 多伦多大学的英语教授亚当哈蒙德也是如此。
正如作者所写,
尽管形式出色,但由于其较低的情感影响和可读性,我们的模型的输出可以很容易地与人类写的诗歌区分开来。 特别是,这里有证据表明我们对形式的关注实际上损害了所产生诗歌的可读性。
然而,人工智能对信息过载的偏爱只会随着越来越多的学者将人类诗歌置于分析技术之下而增加,这些分析技术采用大量文本调查,然后可以对其进行切片和切块。
例如,斯图加特大学的 Thomas Nikolaus Haider 和达姆施塔特工业大学的 Steffen Eger 在 2019 年编制了一个包含 269 位作者的 75,000 首德语诗歌的语料库,时间跨度从 16 世纪至今。 他们指出,这是“迄今为止最大的诗集”。
作者分析了诗歌中的“比喻”,意思是用重复出现的语言表达给定概念的模式——再一次,可以量化的事物。
作者使用一种熟悉的机器学习技术,即给并列的单词打分,发现诸如“爱是魔法”之类的比喻在 18 世纪和 19 世纪的德国浪漫主义时期越来越流行。 他们将其与流行度越来越低的短语进行比较,例如“爱的鼓声”。
关键是,通过大量数据收集和新的分析工具,对诗歌统计的研究支持了这样一种感觉,即存在模式,至少是形式模式,是创作冲动的基础,因此必须有 可以被适当的程序捕获的东西。
所有这一切的重点是,大多数人似乎无法区分机器的书写和人的书写之间的区别,即使他们能分辨出来,他们也不一定在意。
在一月份的一篇论文中,阿姆斯特丹大学和马克斯普朗克研究所的 Nils Köbis 和 Luca D. Mossink 向人们询问了一篇题为“人工智能与 Maya Angelou:人们无法区分 AI 生成的诗歌与人类创作的诗歌的实验证据”的有趣论文。 在两首以同一行开头的诗中选择他们更喜欢哪首,一首由一个人完成,一首由 GPT-2 完成。
在多个不同的测试设置中,作者发现“人们无法可靠地识别人类与算法的创意内容。”
此外,许多人表示他们对机器创作的诗歌没有意见,即使他们事先被告知他们正在阅读算法的作品。
在另一项研究中,佛罗伦萨大学和锡耶纳大学的 Andrea Zugarini 及其同事于 2019 年生成了三句诗,这是一首诗中的三行单元,并要求人类从但丁·阿利吉耶里 (Dante Alighieri) 的诗歌杰作《神曲》中自己的三句诗中分辨出来。
天真的人类法官,那些在但丁研究方面没有特殊背景的人,几乎有一半的时间判断生成的 tercets 确实是由但丁编写的,基本上是掷硬币。 但丁专家表现更好。
Zugarini 和他的同事得出结论,即使在其他方面失败了,他们的作品也能够“保持神曲的节奏和韵律”。
随着研究人员在构建此类正式评估方面做得越来越好,在这种情况下,人类愿意接受接近表面质量的机器是有效的,那么对人类艺术的担忧可能会消退。
因此,人类与 AI 合作的黄金时代可能即将展开,对句、三句和绝句的出现速度比你想象的还要快









